Daily Edition
The expanded edition keeps the full analyst notes, paper breakdowns, geopolitical framing, and the complete feed selected into this run.
Topic of the day.
A dedicated daily topic chosen from the strongest signals in the run, with TL;DR, why-now framing, and a fuller analyst read.
No AI deep-dive topic today
No analyst notes are available for this topic.
No supporting source trail is available for this topic.
Policy, chips, capital, and power.
Industrial strategy, compute supply, export controls, and big-company positioning shaping the AI balance of power.
From model to agent: Equipping the Responses API with a computer environment
How OpenAI built an agent runtime using the Responses API, shell tool, and hosted containers to run secure, scalable agents with files, tools, and state.
From model to agent: Equipping the Responses API with a computer environment matters because it affects the policy, supply-chain, or security constraints around AI development, especially across compute, state, agent.
- Primary signals: compute, state, agent.
- Source context: OpenAI News published or updated this item on 03/11/2026.

The Download: how AI is used for military targeting, and the Pentagon’s war on Claude
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology. Defense official reveals how AI chatbots could be used for targeting decisions The US military might use generative AI systems to rank...
The Download: how AI is used for military targeting, and the Pentagon’s war on Claude matters because it affects the policy, supply-chain, or security constraints around AI development, especially across defense, military, chatbot.
- Primary signals: defense, military, chatbot.
- Source context: MIT Tech Review published or updated this item on 03/13/2026.

Future AI chips could be built on glass
Human-made glass is thousands of years old. But it’s now poised to find its way into the AI chips used in the world’s newest and largest data centers. This year, a South Korean company called Absolics is planning to start commercial production of special glass panels designed...
Future AI chips could be built on glass matters because it affects the policy, supply-chain, or security constraints around AI development, especially across chip, chips.
- Primary signals: chip, chips.
- Source context: MIT Tech Review published or updated this item on 03/13/2026.
Alibaba Debuts OpenClaw App to Feed China’s Agentic AI Addiction
Alibaba Debuts OpenClaw App to Feed China’s Agentic AI Addiction Bloomberg.com
Alibaba Debuts OpenClaw App to Feed China’s Agentic AI Addiction matters because it affects the policy, supply-chain, or security constraints around AI development, especially across china, agent.
- Primary signals: china, agent.
- Source context: Bloomberg AI published or updated this item on 03/13/2026.
China AI Startup Moonshot Snags Funds at $18 Billion Valuation
China AI Startup Moonshot Snags Funds at $18 Billion Valuation Bloomberg.com
China AI Startup Moonshot Snags Funds at $18 Billion Valuation matters because it affects the policy, supply-chain, or security constraints around AI development, especially across china.
- Primary signals: china.
- Source context: Bloomberg AI published or updated this item on 03/14/2026.
Product, model, and platform movement.
Software, model, deployment, and competitive stories with the strongest operator and market signal in this edition.
Designing AI agents to resist prompt injection
How ChatGPT defends against prompt injection and social engineering by constraining risky actions and protecting sensitive data in agent workflows.
Designing AI agents to resist prompt injection matters because it signals momentum in agent, agents, gpt and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, agents, gpt.
- Source context: OpenAI News published or updated this item on 03/11/2026.

Why physical AI is becoming manufacturing’s next advantage
For decades, manufacturers have pursued automation to drive efficiency, reduce costs, and stabilize operations. That approach delivered meaningful gains, but it is no longer enough. Today’s manufacturing leaders face a different challenge: how to grow amid labor constraints,...
Why physical AI is becoming manufacturing’s next advantage matters because it signals momentum in safety and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: safety.
- Source context: MIT Tech Review published or updated this item on 03/13/2026.

Can AI help predict which heart-failure patients will worsen within a year?
Researchers at MIT, Mass General Brigham, and Harvard Medical School developed a deep-learning model to forecast a patient’s heart failure prognosis up to a year in advance.
Can AI help predict which heart-failure patients will worsen within a year? matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: MIT News AI published or updated this item on 03/12/2026.
US Sends Intercept Drones Used in Ukraine to Blunt Iran Strikes
US Sends Intercept Drones Used in Ukraine to Blunt Iran Strikes Bloomberg.com
US Sends Intercept Drones Used in Ukraine to Blunt Iran Strikes matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Bloomberg AI published or updated this item on 03/13/2026.

Listen Labs raises $69M after viral billboard hiring stunt to scale AI customer interviews
Alfred Wahlforss was running out of options. His startup, Listen Labs , needed to hire over 100 engineers, but competing against Mark Zuckerberg's $100 million offers seemed impossible. So he spent $5,000 — a fifth of his marketing budget — on a billboard in San Francisco...
Listen Labs raises $69M after viral billboard hiring stunt to scale AI customer interviews matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: VentureBeat AI published or updated this item on 01/16/2026.
Differentiated source coverage.
Stories drawn from research blogs, first-party lab posts, practitioner newsletters, and selected technical outlets so the edition does not mirror the same headline across every source.
No source-watch items today.
Method, limitations, and results.
Paper summaries, methodology notes, limitations, and deep-dive bullets for the research items selected into the digest.

Strategic Navigation or Stochastic Search? How Agents and Humans Reason Over Document Collections
TL;DR: MADQA benchmark evaluates multimodal agents' strategic reasoning capabilities through diverse PDF document questions, revealing gaps between human-level accuracy and efficient reasoning performance.
MADQA benchmark evaluates multimodal agents' strategic reasoning capabilities through diverse PDF document questions, revealing gaps between human-level accuracy and efficient reasoning performance. Multimodal agents offer a promising path to automating complex...
MADQA benchmark evaluates multimodal agents' strategic reasoning capabilities through diverse PDF document questions, revealing gaps between human-level accuracy and efficient reasoning performance.
To address this, we introduce MADQA, a benchmark of 2,250 human-authored questions grounded in 800 heterogeneous PDF documents.
MADQA benchmark evaluates multimodal agents' strategic reasoning capabilities through diverse PDF document questions, revealing gaps between human-level accuracy and efficient reasoning performance.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: MADQA benchmark evaluates multimodal agents' strategic reasoning capabilities through diverse PDF document questions, revealing gaps between human-level accuracy and efficient reasoning performance.
- Method signal: To address this, we introduce MADQA, a benchmark of 2,250 human-authored questions grounded in 800 heterogeneous PDF documents.
- Evidence to watch: MADQA benchmark evaluates multimodal agents' strategic reasoning capabilities through diverse PDF document questions, revealing gaps between human-level accuracy and efficient reasoning performance.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: MADQA benchmark evaluates multimodal agents' strategic reasoning capabilities through diverse PDF document questions, revealing gaps between human-level accuracy and efficient reasoning performance.
- Approach: To address this, we introduce MADQA, a benchmark of 2,250 human-authored questions grounded in 800 heterogeneous PDF documents.
- Result signal: MADQA benchmark evaluates multimodal agents' strategic reasoning capabilities through diverse PDF document questions, revealing gaps between human-level accuracy and efficient reasoning performance.
- Community traction: Hugging Face Papers shows 45 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.

AvaTaR: Optimizing LLM Agents for Tool Usage via Contrastive Reasoning
TL;DR: Large language model (LLM) agents have demonstrated impressive capabilities in utilizing external tools and knowledge to boost accuracy and reduce hallucinations.
Large language model (LLM) agents have demonstrated impressive capabilities in utilizing external tools and knowledge to boost accuracy and reduce hallucinations. However, developing prompting techniques that enable LLM agents to effectively use these tools and knowledge...
However, developing prompting techniques that enable LLM agents to effectively use these tools and knowledge remains a heuristic and labor-intensive task.
Here, we introduce AvaTaR, a novel and automated framework that optimizes an LLM agent to effectively leverage provided tools, improving performance on a given task.
Large language model (LLM) agents have demonstrated impressive capabilities in utilizing external tools and knowledge to boost accuracy and reduce hallucinations.
The abstract is promising, but we still need to inspect the full paper for compute cost, implementation complexity, and how broadly the gains transfer beyond the reported benchmarks.
- Problem framing: However, developing prompting techniques that enable LLM agents to effectively use these tools and knowledge remains a heuristic and labor-intensive task.
- Method signal: Here, we introduce AvaTaR, a novel and automated framework that optimizes an LLM agent to effectively leverage provided tools, improving performance on a given task.
- Evidence to watch: Large language model (LLM) agents have demonstrated impressive capabilities in utilizing external tools and knowledge to boost accuracy and reduce hallucinations.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from NeurIPS 2024.
- Problem: However, developing prompting techniques that enable LLM agents to effectively use these tools and knowledge remains a heuristic and labor-intensive task.
- Approach: Here, we introduce AvaTaR, a novel and automated framework that optimizes an LLM agent to effectively leverage provided tools, improving performance on a given task.
- Result signal: Large language model (LLM) agents have demonstrated impressive capabilities in utilizing external tools and knowledge to boost accuracy and reduce hallucinations.
- Conference context: NeurIPS 2024 Main Conference Track
- The abstract is promising, but we still need to inspect the full paper for compute cost, implementation complexity, and how broadly the gains transfer beyond the reported benchmarks.

Optimus-1: Hybrid Multimodal Memory Empowered Agents Excel in Long-Horizon Tasks
TL;DR: Building a general-purpose agent is a long-standing vision in the field of artificial intelligence.
Building a general-purpose agent is a long-standing vision in the field of artificial intelligence. Existing agents have made remarkable progress in many domains, yet they still struggle to complete long-horizon tasks in an open world. We attribute this to the lack of...
Existing agents have made remarkable progress in many domains, yet they still struggle to complete long-horizon tasks in an open world.
In this paper, we propose a Hybrid Multimodal Memory module to address the above challenges.
Extensive experimental results show that Optimus-1 significantly outperforms all existing agents on challenging long-horizon task benchmarks, and exhibits near human-level performance on many tasks.
The abstract is promising, but we still need to inspect the full paper for compute cost, implementation complexity, and how broadly the gains transfer beyond the reported benchmarks.
- Problem framing: Existing agents have made remarkable progress in many domains, yet they still struggle to complete long-horizon tasks in an open world.
- Method signal: In this paper, we propose a Hybrid Multimodal Memory module to address the above challenges.
- Evidence to watch: Extensive experimental results show that Optimus-1 significantly outperforms all existing agents on challenging long-horizon task benchmarks, and exhibits near human-level performance on many tasks.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from NeurIPS 2024.
- Problem: Existing agents have made remarkable progress in many domains, yet they still struggle to complete long-horizon tasks in an open world.
- Approach: In this paper, we propose a Hybrid Multimodal Memory module to address the above challenges.
- Result signal: Extensive experimental results show that Optimus-1 significantly outperforms all existing agents on challenging long-horizon task benchmarks, and exhibits near human-level performance on many tasks.
- Conference context: NeurIPS 2024 Main Conference Track
- The abstract is promising, but we still need to inspect the full paper for compute cost, implementation complexity, and how broadly the gains transfer beyond the reported benchmarks.

Spatial-TTT: Streaming Visual-based Spatial Intelligence with Test-Time Training
TL;DR: Spatial-TTT enables streaming visual-based spatial intelligence through test-time training that adapts parameters to capture spatial evidence over long video sequences using hybrid architecture and 3D spatiotemporal...
Spatial-TTT enables streaming visual-based spatial intelligence through test-time training that adapts parameters to capture spatial evidence over long video sequences using hybrid architecture and 3D spatiotemporal convolution. Humans perceive and understand real-world...
The core challenge is not simply longer context windows but how spatial information is selected, organized, and retained over time.
In this paper, we propose Spatial-TTT towards streaming visual-based spatial intelligence with test-time training (TTT), which adapts a subset of parameters ( fast weights ) to capture and organize spatial evidence over long-horizon scene videos .
Extensive experiments demonstrate that Spatial-TTT improves long-horizon spatial understanding and achieves state-of-the-art performance on video spatial benchmarks .
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: The core challenge is not simply longer context windows but how spatial information is selected, organized, and retained over time.
- Method signal: In this paper, we propose Spatial-TTT towards streaming visual-based spatial intelligence with test-time training (TTT), which adapts a subset of parameters ( fast weights ) to capture and organize spatial evidence over long-horizon scene...
- Evidence to watch: Extensive experiments demonstrate that Spatial-TTT improves long-horizon spatial understanding and achieves state-of-the-art performance on video spatial benchmarks .
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: The core challenge is not simply longer context windows but how spatial information is selected, organized, and retained over time.
- Approach: In this paper, we propose Spatial-TTT towards streaming visual-based spatial intelligence with test-time training (TTT), which adapts a subset of parameters ( fast weights ) to capture and organize spatial...
- Result signal: Extensive experiments demonstrate that Spatial-TTT improves long-horizon spatial understanding and achieves state-of-the-art performance on video spatial benchmarks .
- Community traction: Hugging Face Papers shows 66 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
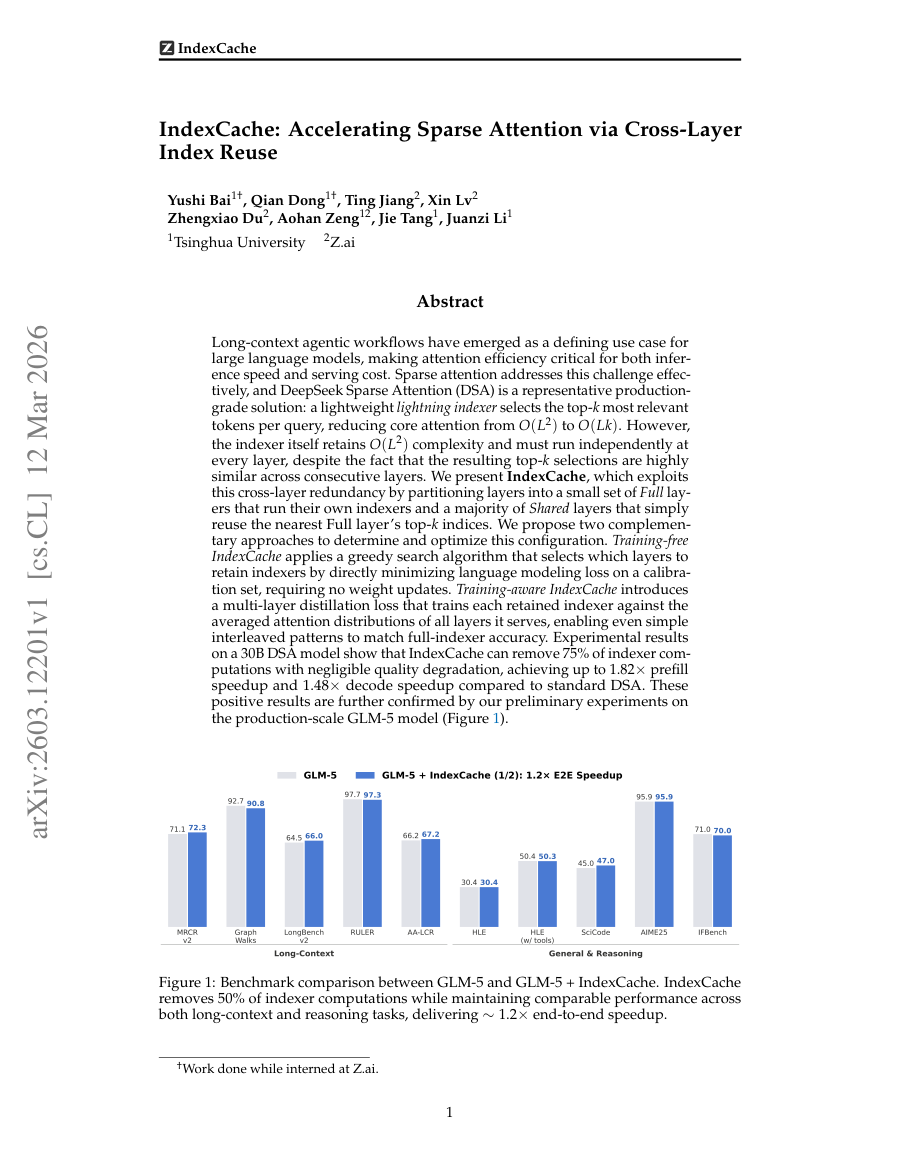
IndexCache: Accelerating Sparse Attention via Cross-Layer Index Reuse
TL;DR: IndexCache reduces sparse attention computation in large language models by reusing top-k token selections across layers, achieving significant speedups with minimal quality loss.
IndexCache reduces sparse attention computation in large language models by reusing top-k token selections across layers, achieving significant speedups with minimal quality loss. Long-context agentic workflows have emerged as a defining use case for large language models,...
Sparse attention addresses this challenge effectively, and DeepSeek Sparse Attention (DSA) is a representative production-grade solution: a lightweight lightning indexer selects the top-k most relevant tokens per query, reducing core attention from O(L^2)...
We present IndexCache, which exploits this cross-layer redundancy by partitioning layers into a small set of Full layers that run their own indexer s and a majority of Shared layers that simply reuse the nearest Full layer's top-k indices.
IndexCache reduces sparse attention computation in large language models by reusing top-k token selections across layers, achieving significant speedups with minimal quality loss.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: Sparse attention addresses this challenge effectively, and DeepSeek Sparse Attention (DSA) is a representative production-grade solution: a lightweight lightning indexer selects the top-k most relevant tokens per query, reducing core...
- Method signal: We present IndexCache, which exploits this cross-layer redundancy by partitioning layers into a small set of Full layers that run their own indexer s and a majority of Shared layers that simply reuse the nearest Full layer's top-k indices.
- Evidence to watch: IndexCache reduces sparse attention computation in large language models by reusing top-k token selections across layers, achieving significant speedups with minimal quality loss.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: Sparse attention addresses this challenge effectively, and DeepSeek Sparse Attention (DSA) is a representative production-grade solution: a lightweight lightning indexer selects the top-k most relevant...
- Approach: We present IndexCache, which exploits this cross-layer redundancy by partitioning layers into a small set of Full layers that run their own indexer s and a majority of Shared layers that simply reuse the...
- Result signal: IndexCache reduces sparse attention computation in large language models by reusing top-k token selections across layers, achieving significant speedups with minimal quality loss.
- Community traction: Hugging Face Papers shows 34 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
Everything selected into the run.
The complete analyzed stream for the issue, useful when you want to scan the entire run instead of only the curated front page.
Spatial-TTT: Streaming Visual-based Spatial Intelligence with Test-Time Training
TL;DR: Spatial-TTT enables streaming visual-based spatial intelligence through test-time training that adapts parameters to capture spatial evidence over long video sequences using hybrid architecture and 3D spatiotemporal...
Spatial-TTT enables streaming visual-based spatial intelligence through test-time training that adapts parameters to capture spatial evidence over long video sequences using hybrid architecture and 3D spatiotemporal convolution. Humans perceive and understand real-world...
The core challenge is not simply longer context windows but how spatial information is selected, organized, and retained over time.
In this paper, we propose Spatial-TTT towards streaming visual-based spatial intelligence with test-time training (TTT), which adapts a subset of parameters ( fast weights ) to capture and organize spatial evidence over long-horizon scene videos .
Extensive experiments demonstrate that Spatial-TTT improves long-horizon spatial understanding and achieves state-of-the-art performance on video spatial benchmarks .
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: The core challenge is not simply longer context windows but how spatial information is selected, organized, and retained over time.
- Method signal: In this paper, we propose Spatial-TTT towards streaming visual-based spatial intelligence with test-time training (TTT), which adapts a subset of parameters ( fast weights ) to capture and organize spatial evidence over long-horizon scene...
- Evidence to watch: Extensive experiments demonstrate that Spatial-TTT improves long-horizon spatial understanding and achieves state-of-the-art performance on video spatial benchmarks .
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: The core challenge is not simply longer context windows but how spatial information is selected, organized, and retained over time.
- Approach: In this paper, we propose Spatial-TTT towards streaming visual-based spatial intelligence with test-time training (TTT), which adapts a subset of parameters ( fast weights ) to capture and organize spatial...
- Result signal: Extensive experiments demonstrate that Spatial-TTT improves long-horizon spatial understanding and achieves state-of-the-art performance on video spatial benchmarks .
- Community traction: Hugging Face Papers shows 66 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
Strategic Navigation or Stochastic Search? How Agents and Humans Reason Over Document Collections
TL;DR: MADQA benchmark evaluates multimodal agents' strategic reasoning capabilities through diverse PDF document questions, revealing gaps between human-level accuracy and efficient reasoning performance.
MADQA benchmark evaluates multimodal agents' strategic reasoning capabilities through diverse PDF document questions, revealing gaps between human-level accuracy and efficient reasoning performance. Multimodal agents offer a promising path to automating complex...
MADQA benchmark evaluates multimodal agents' strategic reasoning capabilities through diverse PDF document questions, revealing gaps between human-level accuracy and efficient reasoning performance.
To address this, we introduce MADQA, a benchmark of 2,250 human-authored questions grounded in 800 heterogeneous PDF documents.
MADQA benchmark evaluates multimodal agents' strategic reasoning capabilities through diverse PDF document questions, revealing gaps between human-level accuracy and efficient reasoning performance.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: MADQA benchmark evaluates multimodal agents' strategic reasoning capabilities through diverse PDF document questions, revealing gaps between human-level accuracy and efficient reasoning performance.
- Method signal: To address this, we introduce MADQA, a benchmark of 2,250 human-authored questions grounded in 800 heterogeneous PDF documents.
- Evidence to watch: MADQA benchmark evaluates multimodal agents' strategic reasoning capabilities through diverse PDF document questions, revealing gaps between human-level accuracy and efficient reasoning performance.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: MADQA benchmark evaluates multimodal agents' strategic reasoning capabilities through diverse PDF document questions, revealing gaps between human-level accuracy and efficient reasoning performance.
- Approach: To address this, we introduce MADQA, a benchmark of 2,250 human-authored questions grounded in 800 heterogeneous PDF documents.
- Result signal: MADQA benchmark evaluates multimodal agents' strategic reasoning capabilities through diverse PDF document questions, revealing gaps between human-level accuracy and efficient reasoning performance.
- Community traction: Hugging Face Papers shows 45 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
IndexCache: Accelerating Sparse Attention via Cross-Layer Index Reuse
TL;DR: IndexCache reduces sparse attention computation in large language models by reusing top-k token selections across layers, achieving significant speedups with minimal quality loss.
IndexCache reduces sparse attention computation in large language models by reusing top-k token selections across layers, achieving significant speedups with minimal quality loss. Long-context agentic workflows have emerged as a defining use case for large language models,...
Sparse attention addresses this challenge effectively, and DeepSeek Sparse Attention (DSA) is a representative production-grade solution: a lightweight lightning indexer selects the top-k most relevant tokens per query, reducing core attention from O(L^2)...
We present IndexCache, which exploits this cross-layer redundancy by partitioning layers into a small set of Full layers that run their own indexer s and a majority of Shared layers that simply reuse the nearest Full layer's top-k indices.
IndexCache reduces sparse attention computation in large language models by reusing top-k token selections across layers, achieving significant speedups with minimal quality loss.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: Sparse attention addresses this challenge effectively, and DeepSeek Sparse Attention (DSA) is a representative production-grade solution: a lightweight lightning indexer selects the top-k most relevant tokens per query, reducing core...
- Method signal: We present IndexCache, which exploits this cross-layer redundancy by partitioning layers into a small set of Full layers that run their own indexer s and a majority of Shared layers that simply reuse the nearest Full layer's top-k indices.
- Evidence to watch: IndexCache reduces sparse attention computation in large language models by reusing top-k token selections across layers, achieving significant speedups with minimal quality loss.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: Sparse attention addresses this challenge effectively, and DeepSeek Sparse Attention (DSA) is a representative production-grade solution: a lightweight lightning indexer selects the top-k most relevant...
- Approach: We present IndexCache, which exploits this cross-layer redundancy by partitioning layers into a small set of Full layers that run their own indexer s and a majority of Shared layers that simply reuse the...
- Result signal: IndexCache reduces sparse attention computation in large language models by reusing top-k token selections across layers, achieving significant speedups with minimal quality loss.
- Community traction: Hugging Face Papers shows 34 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
Optimus-1: Hybrid Multimodal Memory Empowered Agents Excel in Long-Horizon Tasks
TL;DR: Building a general-purpose agent is a long-standing vision in the field of artificial intelligence.
Building a general-purpose agent is a long-standing vision in the field of artificial intelligence. Existing agents have made remarkable progress in many domains, yet they still struggle to complete long-horizon tasks in an open world. We attribute this to the lack of...
Existing agents have made remarkable progress in many domains, yet they still struggle to complete long-horizon tasks in an open world.
In this paper, we propose a Hybrid Multimodal Memory module to address the above challenges.
Extensive experimental results show that Optimus-1 significantly outperforms all existing agents on challenging long-horizon task benchmarks, and exhibits near human-level performance on many tasks.
The abstract is promising, but we still need to inspect the full paper for compute cost, implementation complexity, and how broadly the gains transfer beyond the reported benchmarks.
- Problem framing: Existing agents have made remarkable progress in many domains, yet they still struggle to complete long-horizon tasks in an open world.
- Method signal: In this paper, we propose a Hybrid Multimodal Memory module to address the above challenges.
- Evidence to watch: Extensive experimental results show that Optimus-1 significantly outperforms all existing agents on challenging long-horizon task benchmarks, and exhibits near human-level performance on many tasks.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from NeurIPS 2024.
- Problem: Existing agents have made remarkable progress in many domains, yet they still struggle to complete long-horizon tasks in an open world.
- Approach: In this paper, we propose a Hybrid Multimodal Memory module to address the above challenges.
- Result signal: Extensive experimental results show that Optimus-1 significantly outperforms all existing agents on challenging long-horizon task benchmarks, and exhibits near human-level performance on many tasks.
- Conference context: NeurIPS 2024 Main Conference Track
- The abstract is promising, but we still need to inspect the full paper for compute cost, implementation complexity, and how broadly the gains transfer beyond the reported benchmarks.
AvaTaR: Optimizing LLM Agents for Tool Usage via Contrastive Reasoning
TL;DR: Large language model (LLM) agents have demonstrated impressive capabilities in utilizing external tools and knowledge to boost accuracy and reduce hallucinations.
Large language model (LLM) agents have demonstrated impressive capabilities in utilizing external tools and knowledge to boost accuracy and reduce hallucinations. However, developing prompting techniques that enable LLM agents to effectively use these tools and knowledge...
However, developing prompting techniques that enable LLM agents to effectively use these tools and knowledge remains a heuristic and labor-intensive task.
Here, we introduce AvaTaR, a novel and automated framework that optimizes an LLM agent to effectively leverage provided tools, improving performance on a given task.
Large language model (LLM) agents have demonstrated impressive capabilities in utilizing external tools and knowledge to boost accuracy and reduce hallucinations.
The abstract is promising, but we still need to inspect the full paper for compute cost, implementation complexity, and how broadly the gains transfer beyond the reported benchmarks.
- Problem framing: However, developing prompting techniques that enable LLM agents to effectively use these tools and knowledge remains a heuristic and labor-intensive task.
- Method signal: Here, we introduce AvaTaR, a novel and automated framework that optimizes an LLM agent to effectively leverage provided tools, improving performance on a given task.
- Evidence to watch: Large language model (LLM) agents have demonstrated impressive capabilities in utilizing external tools and knowledge to boost accuracy and reduce hallucinations.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from NeurIPS 2024.
- Problem: However, developing prompting techniques that enable LLM agents to effectively use these tools and knowledge remains a heuristic and labor-intensive task.
- Approach: Here, we introduce AvaTaR, a novel and automated framework that optimizes an LLM agent to effectively leverage provided tools, improving performance on a given task.
- Result signal: Large language model (LLM) agents have demonstrated impressive capabilities in utilizing external tools and knowledge to boost accuracy and reduce hallucinations.
- Conference context: NeurIPS 2024 Main Conference Track
- The abstract is promising, but we still need to inspect the full paper for compute cost, implementation complexity, and how broadly the gains transfer beyond the reported benchmarks.
Alibaba Debuts OpenClaw App to Feed China’s Agentic AI Addiction
Alibaba Debuts OpenClaw App to Feed China’s Agentic AI Addiction Bloomberg.com
Alibaba Debuts OpenClaw App to Feed China’s Agentic AI Addiction matters because it affects the policy, supply-chain, or security constraints around AI development, especially across china, agent.
- Primary signals: china, agent.
- Source context: Bloomberg AI published or updated this item on 03/13/2026.
‘God, It’s Terrifying’: How the Pentagon Got Hooked on AI War Machines
‘God, It’s Terrifying’: How the Pentagon Got Hooked on AI War Machines Bloomberg.com
‘God, It’s Terrifying’: How the Pentagon Got Hooked on AI War Machines matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Bloomberg AI published or updated this item on 03/12/2026.
US Sends Intercept Drones Used in Ukraine to Blunt Iran Strikes
US Sends Intercept Drones Used in Ukraine to Blunt Iran Strikes Bloomberg.com
US Sends Intercept Drones Used in Ukraine to Blunt Iran Strikes matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Bloomberg AI published or updated this item on 03/13/2026.
China AI Startup Moonshot Snags Funds at $18 Billion Valuation
China AI Startup Moonshot Snags Funds at $18 Billion Valuation Bloomberg.com
China AI Startup Moonshot Snags Funds at $18 Billion Valuation matters because it affects the policy, supply-chain, or security constraints around AI development, especially across china.
- Primary signals: china.
- Source context: Bloomberg AI published or updated this item on 03/14/2026.
Rakuten fixes issues twice as fast with Codex
Rakuten uses Codex, the coding agent from OpenAI, to ship software faster and safer, reducing MTTR 50%, automating CI/CD reviews, and delivering full-stack builds in weeks.
Rakuten fixes issues twice as fast with Codex matters because it signals momentum in agent and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent.
- Source context: OpenAI News published or updated this item on 03/11/2026.
Designing AI agents to resist prompt injection
How ChatGPT defends against prompt injection and social engineering by constraining risky actions and protecting sensitive data in agent workflows.
Designing AI agents to resist prompt injection matters because it signals momentum in agent, agents, gpt and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, agents, gpt.
- Source context: OpenAI News published or updated this item on 03/11/2026.
From model to agent: Equipping the Responses API with a computer environment
How OpenAI built an agent runtime using the Responses API, shell tool, and hosted containers to run secure, scalable agents with files, tools, and state.
From model to agent: Equipping the Responses API with a computer environment matters because it affects the policy, supply-chain, or security constraints around AI development, especially across compute, state, agent.
- Primary signals: compute, state, agent.
- Source context: OpenAI News published or updated this item on 03/11/2026.
Can AI help predict which heart-failure patients will worsen within a year?
Researchers at MIT, Mass General Brigham, and Harvard Medical School developed a deep-learning model to forecast a patient’s heart failure prognosis up to a year in advance.
Can AI help predict which heart-failure patients will worsen within a year? matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: MIT News AI published or updated this item on 03/12/2026.
3 Questions: On the future of AI and the mathematical and physical sciences
Professor Jesse Thaler describes a vision for a two-way bridge between artificial intelligence and the mathematical and physical sciences — one that promises to advance both.
3 Questions: On the future of AI and the mathematical and physical sciences matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: MIT News AI published or updated this item on 03/11/2026.

New MIT class uses anthropology to improve chatbots
MIT computer science students design AI chatbots to help young users become more social, and socially confident.
New MIT class uses anthropology to improve chatbots matters because it affects the policy, supply-chain, or security constraints around AI development, especially across compute, chatbot.
- Primary signals: compute, chatbot.
- Source context: MIT News AI published or updated this item on 03/11/2026.
Why physical AI is becoming manufacturing’s next advantage
For decades, manufacturers have pursued automation to drive efficiency, reduce costs, and stabilize operations. That approach delivered meaningful gains, but it is no longer enough. Today’s manufacturing leaders face a different challenge: how to grow amid labor constraints,...
Why physical AI is becoming manufacturing’s next advantage matters because it signals momentum in safety and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: safety.
- Source context: MIT Tech Review published or updated this item on 03/13/2026.
The Download: how AI is used for military targeting, and the Pentagon’s war on Claude
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology. Defense official reveals how AI chatbots could be used for targeting decisions The US military might use generative AI systems to rank...
The Download: how AI is used for military targeting, and the Pentagon’s war on Claude matters because it affects the policy, supply-chain, or security constraints around AI development, especially across defense, military, chatbot.
- Primary signals: defense, military, chatbot.
- Source context: MIT Tech Review published or updated this item on 03/13/2026.
Future AI chips could be built on glass
Human-made glass is thousands of years old. But it’s now poised to find its way into the AI chips used in the world’s newest and largest data centers. This year, a South Korean company called Absolics is planning to start commercial production of special glass panels designed...
Future AI chips could be built on glass matters because it affects the policy, supply-chain, or security constraints around AI development, especially across chip, chips.
- Primary signals: chip, chips.
- Source context: MIT Tech Review published or updated this item on 03/13/2026.
Railway secures $100 million to challenge AWS with AI-native cloud infrastructure
Railway , a San Francisco-based cloud platform that has quietly amassed two million developers without spending a dollar on marketing, announced Thursday that it raised $100 million in a Series B funding round, as surging demand for artificial intelligence applications...
Railway secures $100 million to challenge AWS with AI-native cloud infrastructure matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: VentureBeat AI published or updated this item on 01/22/2026.
Claude Code costs up to $200 a month. Goose does the same thing for free.
The artificial intelligence coding revolution comes with a catch: it's expensive. Claude Code , Anthropic's terminal-based AI agent that can write, debug, and deploy code autonomously, has captured the imagination of software developers worldwide. But its pricing — ranging...
Claude Code costs up to $200 a month. Goose does the same thing for free. matters because it signals momentum in agent and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent.
- Source context: VentureBeat AI published or updated this item on 01/19/2026.
Listen Labs raises $69M after viral billboard hiring stunt to scale AI customer interviews
Alfred Wahlforss was running out of options. His startup, Listen Labs , needed to hire over 100 engineers, but competing against Mark Zuckerberg's $100 million offers seemed impossible. So he spent $5,000 — a fifth of his marketing budget — on a billboard in San Francisco...
Listen Labs raises $69M after viral billboard hiring stunt to scale AI customer interviews matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: VentureBeat AI published or updated this item on 01/16/2026.
Issue routing and exits.
The daily edition stays aligned with the rest of the site while keeping the full issue readable end to end.
Navigation
Public desks
Issue
- 03/14/2026
- 21 total analyzed
- Readable issue route