Daily Edition
The expanded edition keeps the full analyst notes, paper breakdowns, geopolitical framing, and the complete feed selected into this run.
Topic of the day.
A dedicated daily topic chosen from the strongest signals in the run, with TL;DR, why-now framing, and a fuller analyst read.
OpenSeeker: Democratizing Frontier Search Agents
TL;DR: OpenSeeker releases fully open-source search agent training data and models, achieving frontier-level performance with only 11.7k synthetic samples, closing the gap with industrial search agents.
Why now: Industrial giants dominate high-performance search agents due to lack of transparent, high-quality training data; OpenSeeker's open data and training recipe enable community replication and innovation.
Fact-grounded scalable controllable QA synthesis generates complex multi-hop reasoning tasks by reverse-engineering the web graph; Denoised trajectory synthesis uses retrospective summarization to improve teacher LLM action quality; Trained on just 11.7k samples via simple SFT, OpenSeeker outperforms prior open-source agents and rivals industrial models on multiple benchmarks; The release of both model and data lowers barriers for academic research and encourages reproducible advances in agentic search.
- First fully open-source search agent (model + data) with frontier performance.
- Two core innovations: Fact-grounded QA synthesis and Denoised trajectory synthesis.
- Achieves 29.5% on BrowseComp vs 15.3% for DeepDive; 48.4% on BrowseComp-ZH vs Tongyi DeepResearch.
- Only 11.7k synthesized samples needed for a single training run.
- OpenSeeker: Democratizing Frontier Search Agents by Fully Open-Sourcing Training Data (Hugging Face Papers / arXiv | 03/16/2026)
- OpenSeeker GitHub Repository (GitHub | 03/16/2026)
Policy, chips, capital, and power.
Industrial strategy, compute supply, export controls, and big-company positioning shaping the AI balance of power.
From model to agent: Equipping the Responses API with a computer environment
From model to agent: Equipping the Responses API with a computer environment OpenAI
From model to agent: Equipping the Responses API with a computer environment matters because it affects the policy, supply-chain, or security constraints around AI development, especially across compute, agent, model.
- Primary signals: compute, agent, model.
- Source context: OpenAI Research published or updated this item on 03/11/2026.

US Treasury publishes AI risk Guidebook for financial institutions
The US Treasury has published several documents designed for the US financial services sector that suggest a structured approach to managing AI risks in operations and policy (see subheading ‘Resources and Downloads’ towards the bottom of the link). The CRI Financial Services...
US Treasury publishes AI risk Guidebook for financial institutions matters because it affects the policy, supply-chain, or security constraints around AI development, especially across policy.
- Primary signals: policy.
- Source context: AI News published or updated this item on 03/16/2026.
A defense official reveals how AI chatbots could be used for targeting decisions
A defense official reveals how AI chatbots could be used for targeting decisions MIT Technology Review
A defense official reveals how AI chatbots could be used for targeting decisions matters because it affects the policy, supply-chain, or security constraints around AI development, especially across defense, chatbot.
- Primary signals: defense, chatbot.
- Source context: MIT Tech Review AI published or updated this item on 03/12/2026.

BMW puts humanoid robots to work in Germany–and Europe’s factories are watching
Europe’s factory floors have a new kind of colleague. BMW Group has deployed humanoid robots in manufacturing in Germany for the first time, launching a pilot project at its Leipzig plant with AEON–a wheeled humanoid built by Hexagon Robotics. It is the first automotive...
BMW puts humanoid robots to work in Germany–and Europe’s factories are watching matters because it affects the policy, supply-chain, or security constraints around AI development, especially across europe, robotics.
- Primary signals: europe, robotics.
- Source context: AI News published or updated this item on 03/13/2026.
Product, model, and platform movement.
Software, model, deployment, and competitive stories with the strongest operator and market signal in this edition.
Introducing GPT-5.4
OpenAI announces GPT-5.4, the latest iteration of its generative pre-trained transformer series.
Signals continued scaling of model capabilities, potentially improving reasoning and multimodal performance.
- Successor to GPT-5.3 with unspecified architectural improvements.
- Expected to enhance few-shot learning and alignment.
New ways to learn math and science in ChatGPT
OpenAI introduces new educational features in ChatGPT for math and science learning.
Expands AI's role in education, providing personalized tutoring and problem-solving assistance.
- Integration of step-by-step reasoning tools.
- Use of symbolic reasoning engines for math.

OpenAI’s Frontier puts AI agents in a fight SaaS can’t afford to lose
When OpenAI launched Frontier in February, the announcement was described as a platform for enterprise AI agents. What it actually signalled was a challenge to the revenue architecture underpinning the software industry. Frontier is designed to act as a semantic layer in an...
OpenAI’s Frontier puts AI agents in a fight SaaS can’t afford to lose matters because it signals momentum in agent, agents, frontier and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, agents, frontier.
- Source context: AI News published or updated this item on 03/16/2026.

The First Healthcare Robotics Dataset and Foundational Physical AI Models for Healthcare Robotics
A Blog post by NVIDIA on Hugging Face
The First Healthcare Robotics Dataset and Foundational Physical AI Models for Healthcare Robotics matters because it signals momentum in foundation, model, robotics and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: foundation, model, robotics.
- Source context: Hugging Face Blog published or updated this item on 03/16/2026.

NTT DATA and NVIDIA bring enterprise AI factories to production scale
NTT DATA has announced an initiative to deliver NVIDIA-powered platforms designed to give organisations a repeatable, production-ready model for scaling AI. The offering integrates NVIDIA’s GPU-accelerated computing and high-performance networking with NVIDIA AI Enterprise...
NTT DATA and NVIDIA bring enterprise AI factories to production scale matters because it signals momentum in agent, model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, model.
- Source context: AI News published or updated this item on 03/16/2026.
Differentiated source coverage.
Stories drawn from research blogs, first-party lab posts, practitioner newsletters, and selected technical outlets so the edition does not mirror the same headline across every source.
Identifying Interactions at Scale for LLMs
Understanding the behavior of complex machine learning systems, particularly Large Language Models (LLMs), is a critical challenge in modern artificial intelligence. Interpretability research aims to make the decision-making process more transparent to model builders and...
Identifying Interactions at Scale for LLMs matters because it signals momentum in llm, model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: llm, model.
- Source context: BAIR Blog published or updated this item on 03/13/2026.

Bringing Robotics AI to Embedded Platforms: Dataset Recording, VLA Fine‑Tuning, and On‑Device Optimizations
A Blog post by NXP on Hugging Face
Bringing Robotics AI to Embedded Platforms: Dataset Recording, VLA Fine‑Tuning, and On‑Device Optimizations matters because it signals momentum in robotics and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: robotics.
- Source context: Hugging Face Blog published or updated this item on 03/05/2026.
How Balyasny Asset Management built an AI research engine for investing
How Balyasny Asset Management built an AI research engine for investing OpenAI
How Balyasny Asset Management built an AI research engine for investing matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: OpenAI Research published or updated this item on 03/06/2026.
Measuring AI agent autonomy in practice
Measuring AI agent autonomy in practice Anthropic
Measuring AI agent autonomy in practice matters because it signals momentum in agent and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent.
- Source context: Anthropic Research published or updated this item on 02/18/2026.
NVIDIA AI Releases Nemotron-Terminal: A Systematic Data Engineering Pipeline for Scaling LLM Terminal Agents
NVIDIA AI Releases Nemotron-Terminal: A Systematic Data Engineering Pipeline for Scaling LLM Terminal Agents MarkTechPost
NVIDIA AI Releases Nemotron-Terminal: A Systematic Data Engineering Pipeline for Scaling LLM Terminal Agents matters because it signals momentum in agent, agents, llm and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, agents, llm.
- Source context: MarkTechPost published or updated this item on 03/10/2026.

Ai2: Building physical AI with virtual simulation data
Virtual simulation data is driving the development of physical AI across corporate environments, led by initiatives like Ai2’s MolmoBot. Instructing hardware to interact with the real world has historically relied on highly expensive and manually-collected demonstrations....
Ai2: Building physical AI with virtual simulation data matters because it signals momentum in agent, agents, training and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, agents, training.
- Source context: AI News published or updated this item on 03/11/2026.
QuantumBlack: A Global Force in Agentic AI Transformation
QuantumBlack: A Global Force in Agentic AI Transformation AI Magazine
QuantumBlack: A Global Force in Agentic AI Transformation matters because it signals momentum in agent and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent.
- Source context: AI Magazine published or updated this item on 03/16/2026.
Is the Pentagon allowed to surveil Americans with AI?
Is the Pentagon allowed to surveil Americans with AI? MIT Technology Review
Is the Pentagon allowed to surveil Americans with AI? matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: MIT Tech Review AI published or updated this item on 03/06/2026.
Method, limitations, and results.
Paper summaries, methodology notes, limitations, and deep-dive bullets for the research items selected into the digest.
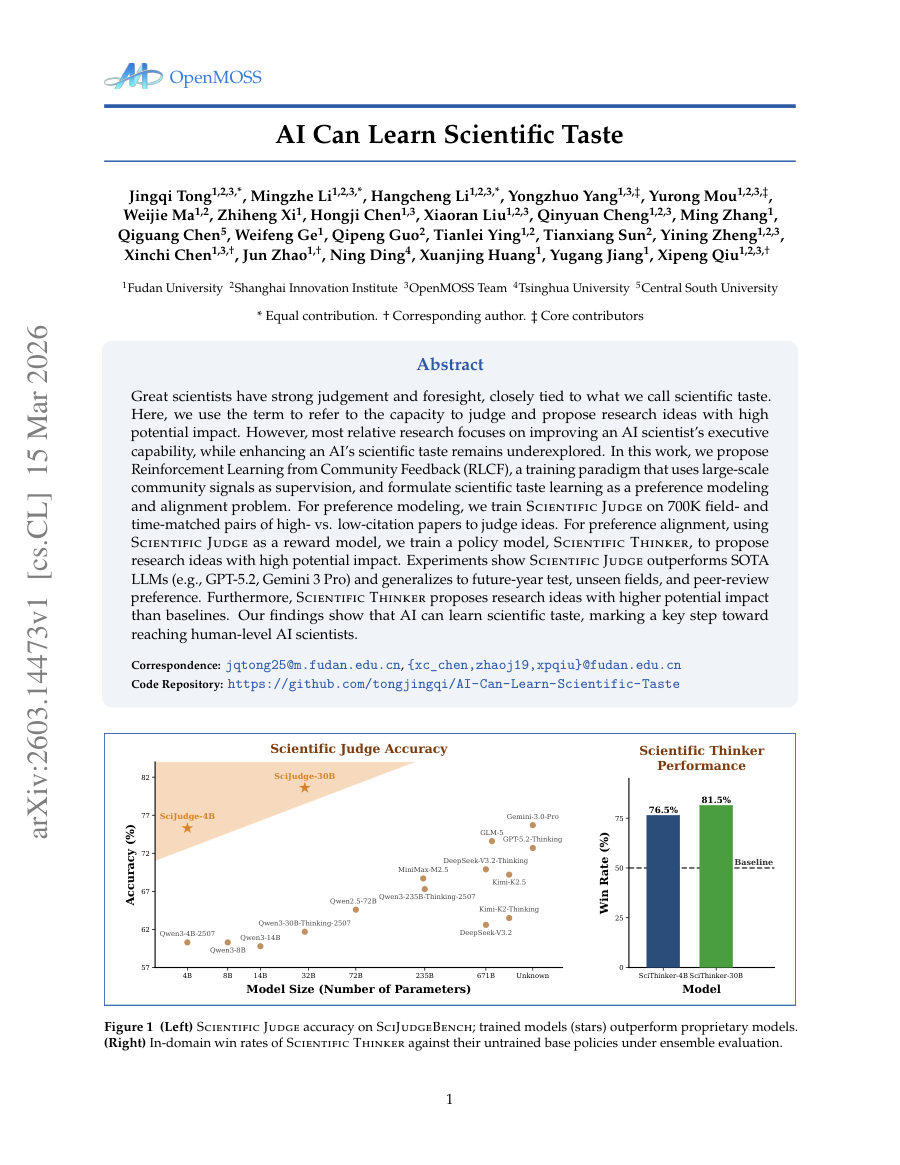
AI Can Learn Scientific Taste
TL;DR: Great scientists have strong judgement and foresight, closely tied to what we call scientific taste.
Great scientists have strong judgement and foresight, closely tied to what we call scientific taste. Here, we use the term to refer to the capacity to judge and propose research ideas with high potential impact. However, most relative research focuses on improving an AI...
In this work, we propose Reinforcement Learning from Community Feedback (RLCF), a training paradigm that uses large-scale community signals as supervision, and formulate scientific taste learning as a preference modeling and alignment problem.
In this work, we propose Reinforcement Learning from Community Feedback (RLCF), a training paradigm that uses large-scale community signals as supervision, and formulate scientific taste learning as a preference modeling and alignment problem.
Experiments show Scientific Judge outperforms SOTA LLMs (e.g., GPT-5.2, Gemini 3 Pro) and generalizes to future-year test, unseen fields, and peer-review preference.
The reported improvement still needs a closer check on benchmark scope, ablations, and whether the method keeps working outside the authors' evaluation setup.
- Problem framing: In this work, we propose Reinforcement Learning from Community Feedback (RLCF), a training paradigm that uses large-scale community signals as supervision, and formulate scientific taste learning as a preference modeling and alignment problem.
- Method signal: In this work, we propose Reinforcement Learning from Community Feedback (RLCF), a training paradigm that uses large-scale community signals as supervision, and formulate scientific taste learning as a preference modeling and alignment problem.
- Evidence to watch: Experiments show Scientific Judge outperforms SOTA LLMs (e.g., GPT-5.2, Gemini 3 Pro) and generalizes to future-year test, unseen fields, and peer-review preference.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: In this work, we propose Reinforcement Learning from Community Feedback (RLCF), a training paradigm that uses large-scale community signals as supervision, and formulate scientific taste learning as a...
- Approach: In this work, we propose Reinforcement Learning from Community Feedback (RLCF), a training paradigm that uses large-scale community signals as supervision, and formulate scientific taste learning as a...
- Result signal: Experiments show Scientific Judge outperforms SOTA LLMs (e.g., GPT-5.2, Gemini 3 Pro) and generalizes to future-year test, unseen fields, and peer-review preference.
- Community traction: Hugging Face Papers shows 58 votes for this paper.
- The reported improvement still needs a closer check on benchmark scope, ablations, and whether the method keeps working outside the authors' evaluation setup.

OpenSeeker: Democratizing Frontier Search Agents by Fully Open-Sourcing Training Data
TL;DR: Deep search capabilities have become an indispensable competency for frontier Large Language Model (LLM) agents, yet the development of high-performance search agents remains dominated by industrial giants due to a...
Deep search capabilities have become an indispensable competency for frontier Large Language Model (LLM) agents, yet the development of high-performance search agents remains dominated by industrial giants due to a lack of transparent, high-quality training data. This...
To bridge this gap, we introduce OpenSeeker, the first fully open-source search agent (i.e., model and data) that achieves frontier-level performance through two core technical innovations: (1) Fact-grounded scalable controllable QA synthesis, which...
To bridge this gap, we introduce OpenSeeker, the first fully open-source search agent (i.e., model and data) that achieves frontier-level performance through two core technical innovations: (1) Fact-grounded scalable controllable QA synthesis, which reverse-engineers the web graph via topological expansion and...
Deep search capabilities have become an indispensable competency for frontier Large Language Model (LLM) agents, yet the development of high-performance search agents remains dominated by industrial giants due to a lack of transparent, high-quality training data.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: To bridge this gap, we introduce OpenSeeker, the first fully open-source search agent (i.e., model and data) that achieves frontier-level performance through two core technical innovations: (1) Fact-grounded scalable controllable QA...
- Method signal: To bridge this gap, we introduce OpenSeeker, the first fully open-source search agent (i.e., model and data) that achieves frontier-level performance through two core technical innovations: (1) Fact-grounded scalable controllable QA...
- Evidence to watch: Deep search capabilities have become an indispensable competency for frontier Large Language Model (LLM) agents, yet the development of high-performance search agents remains dominated by industrial giants due to a lack of transparent,...
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: To bridge this gap, we introduce OpenSeeker, the first fully open-source search agent (i.e., model and data) that achieves frontier-level performance through two core technical innovations: (1) Fact-grounded...
- Approach: To bridge this gap, we introduce OpenSeeker, the first fully open-source search agent (i.e., model and data) that achieves frontier-level performance through two core technical innovations: (1)...
- Result signal: Deep search capabilities have become an indispensable competency for frontier Large Language Model (LLM) agents, yet the development of high-performance search agents remains dominated by industrial...
- Community traction: Hugging Face Papers shows 74 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.

Grounding World Simulation Models in a Real-World Metropolis
TL;DR: What if a world simulation model could render not an imagined environment but a city that actually exists?
What if a world simulation model could render not an imagined environment but a city that actually exists? Prior generative world models synthesize visually plausible yet artificial environments by imagining all content. We present Seoul World Model (SWM), a city-scale world...
However, this design introduces several challenges, including temporal misalignment between retrieved references and the dynamic target scene, limited trajectory diversity and data sparsity from vehicle-mounted captures at sparse intervals.
We present Seoul World Model (SWM), a city-scale world model grounded in the real city of Seoul.
SWM outperforms existing methods in generating spatially faithful, temporally consistent, long-horizon videos grounded in actual urban environments over trajectories reaching hundreds of meters, while supporting diverse camera movements and text-prompted scenario variations.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: However, this design introduces several challenges, including temporal misalignment between retrieved references and the dynamic target scene, limited trajectory diversity and data sparsity from vehicle-mounted captures at sparse intervals.
- Method signal: We present Seoul World Model (SWM), a city-scale world model grounded in the real city of Seoul.
- Evidence to watch: SWM outperforms existing methods in generating spatially faithful, temporally consistent, long-horizon videos grounded in actual urban environments over trajectories reaching hundreds of meters, while supporting diverse camera movements...
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: However, this design introduces several challenges, including temporal misalignment between retrieved references and the dynamic target scene, limited trajectory diversity and data sparsity from...
- Approach: We present Seoul World Model (SWM), a city-scale world model grounded in the real city of Seoul.
- Result signal: SWM outperforms existing methods in generating spatially faithful, temporally consistent, long-horizon videos grounded in actual urban environments over trajectories reaching hundreds of meters, while...
- Community traction: Hugging Face Papers shows 63 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.

HSImul3R: Physics-in-the-Loop Reconstruction of Simulation-Ready Human-Scene Interactions
TL;DR: HSImul3R presents a unified framework for 3D reconstruction of human-scene interactions that bridges the perception-simulation gap through physics-grounded bidirectional optimization and reinforcement learning.
HSImul3R presents a unified framework for 3D reconstruction of human-scene interactions that bridges the perception-simulation gap through physics-grounded bidirectional optimization and reinforcement learning. We present HSImul3R, a unified framework for simulation-ready 3D...
HSImul3R presents a unified framework for 3D reconstruction of human-scene interactions that bridges the perception-simulation gap through physics-grounded bidirectional optimization and reinforcement learning.
We present HSImul3R, a unified framework for simulation-ready 3D reconstruction of human-scene interactions (HSI) from casual captures, including sparse-view images and monocular videos.
Extensive experiments demonstrate that HSImul3R produces the first stable, simulation-ready HSI reconstructions and can be directly deployed to real-world humanoid robots .
The reported improvement still needs a closer check on benchmark scope, ablations, and whether the method keeps working outside the authors' evaluation setup.
- Problem framing: HSImul3R presents a unified framework for 3D reconstruction of human-scene interactions that bridges the perception-simulation gap through physics-grounded bidirectional optimization and reinforcement learning.
- Method signal: We present HSImul3R, a unified framework for simulation-ready 3D reconstruction of human-scene interactions (HSI) from casual captures, including sparse-view images and monocular videos.
- Evidence to watch: Extensive experiments demonstrate that HSImul3R produces the first stable, simulation-ready HSI reconstructions and can be directly deployed to real-world humanoid robots .
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: HSImul3R presents a unified framework for 3D reconstruction of human-scene interactions that bridges the perception-simulation gap through physics-grounded bidirectional optimization and reinforcement learning.
- Approach: We present HSImul3R, a unified framework for simulation-ready 3D reconstruction of human-scene interactions (HSI) from casual captures, including sparse-view images and monocular videos.
- Result signal: Extensive experiments demonstrate that HSImul3R produces the first stable, simulation-ready HSI reconstructions and can be directly deployed to real-world humanoid robots .
- Community traction: Hugging Face Papers shows 17 votes for this paper.
- The reported improvement still needs a closer check on benchmark scope, ablations, and whether the method keeps working outside the authors' evaluation setup.

ViFeEdit: A Video-Free Tuner of Your Video Diffusion Transformer
TL;DR: Diffusion Transformers (DiTs) have demonstrated remarkable scalability and quality in image and video generation, prompting growing interest in extending them to controllable generation and editing tasks.
Diffusion Transformers (DiTs) have demonstrated remarkable scalability and quality in image and video generation, prompting growing interest in extending them to controllable generation and editing tasks. However, compared to the image counterparts, progress in video control...
Diffusion Transformers (DiTs) have demonstrated remarkable scalability and quality in image and video generation, prompting growing interest in extending them to controllable generation and editing tasks.
To address this issue, in this paper, we propose a video-free tuning framework termed ViFeEdit for video diffusion transformers.
Diffusion Transformers (DiTs) have demonstrated remarkable scalability and quality in image and video generation, prompting growing interest in extending them to controllable generation and editing tasks.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: Diffusion Transformers (DiTs) have demonstrated remarkable scalability and quality in image and video generation, prompting growing interest in extending them to controllable generation and editing tasks.
- Method signal: To address this issue, in this paper, we propose a video-free tuning framework termed ViFeEdit for video diffusion transformers.
- Evidence to watch: Diffusion Transformers (DiTs) have demonstrated remarkable scalability and quality in image and video generation, prompting growing interest in extending them to controllable generation and editing tasks.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: Diffusion Transformers (DiTs) have demonstrated remarkable scalability and quality in image and video generation, prompting growing interest in extending them to controllable generation and editing tasks.
- Approach: To address this issue, in this paper, we propose a video-free tuning framework termed ViFeEdit for video diffusion transformers.
- Result signal: Diffusion Transformers (DiTs) have demonstrated remarkable scalability and quality in image and video generation, prompting growing interest in extending them to controllable generation and editing tasks.
- Community traction: Hugging Face Papers shows 14 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
Everything selected into the run.
The complete analyzed stream for the issue, useful when you want to scan the entire run instead of only the curated front page.
Introducing GPT-5.4
OpenAI announces GPT-5.4, the latest iteration of its generative pre-trained transformer series.
Signals continued scaling of model capabilities, potentially improving reasoning and multimodal performance.
- Successor to GPT-5.3 with unspecified architectural improvements.
- Expected to enhance few-shot learning and alignment.
New ways to learn math and science in ChatGPT
OpenAI introduces new educational features in ChatGPT for math and science learning.
Expands AI's role in education, providing personalized tutoring and problem-solving assistance.
- Integration of step-by-step reasoning tools.
- Use of symbolic reasoning engines for math.
OpenAI’s Frontier puts AI agents in a fight SaaS can’t afford to lose
When OpenAI launched Frontier in February, the announcement was described as a platform for enterprise AI agents. What it actually signalled was a challenge to the revenue architecture underpinning the software industry. Frontier is designed to act as a semantic layer in an...
OpenAI’s Frontier puts AI agents in a fight SaaS can’t afford to lose matters because it signals momentum in agent, agents, frontier and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, agents, frontier.
- Source context: AI News published or updated this item on 03/16/2026.
The First Healthcare Robotics Dataset and Foundational Physical AI Models for Healthcare Robotics
A Blog post by NVIDIA on Hugging Face
The First Healthcare Robotics Dataset and Foundational Physical AI Models for Healthcare Robotics matters because it signals momentum in foundation, model, robotics and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: foundation, model, robotics.
- Source context: Hugging Face Blog published or updated this item on 03/16/2026.
NTT DATA and NVIDIA bring enterprise AI factories to production scale
NTT DATA has announced an initiative to deliver NVIDIA-powered platforms designed to give organisations a repeatable, production-ready model for scaling AI. The offering integrates NVIDIA’s GPU-accelerated computing and high-performance networking with NVIDIA AI Enterprise...
NTT DATA and NVIDIA bring enterprise AI factories to production scale matters because it signals momentum in agent, model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, model.
- Source context: AI News published or updated this item on 03/16/2026.
Luma AI's new Uni-1 image model tops Nano Banana 2 and GPT Image 1.5 on logic-based benchmarks
Luma AI's new Uni-1 image model tops Nano Banana 2 and GPT Image 1.5 on logic-based benchmarks the-decoder.com
Luma AI's new Uni-1 image model tops Nano Banana 2 and GPT Image 1.5 on logic-based benchmarks matters because it signals momentum in benchmark, gpt, model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: benchmark, gpt, model.
- Source context: The Decoder published or updated this item on 03/08/2026.
NVIDIA AI Releases Nemotron-Terminal: A Systematic Data Engineering Pipeline for Scaling LLM Terminal Agents
NVIDIA AI Releases Nemotron-Terminal: A Systematic Data Engineering Pipeline for Scaling LLM Terminal Agents MarkTechPost
NVIDIA AI Releases Nemotron-Terminal: A Systematic Data Engineering Pipeline for Scaling LLM Terminal Agents matters because it signals momentum in agent, agents, llm and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, agents, llm.
- Source context: MarkTechPost published or updated this item on 03/10/2026.
Ai2: Building physical AI with virtual simulation data
Virtual simulation data is driving the development of physical AI across corporate environments, led by initiatives like Ai2’s MolmoBot. Instructing hardware to interact with the real world has historically relied on highly expensive and manually-collected demonstrations....
Ai2: Building physical AI with virtual simulation data matters because it signals momentum in agent, agents, training and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, agents, training.
- Source context: AI News published or updated this item on 03/11/2026.
7 Emerging Memory Architectures for AI Agents
7 Emerging Memory Architectures for AI Agents Turing Post
7 Emerging Memory Architectures for AI Agents matters because it signals momentum in agent, agents and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, agents.
- Source context: Turing Post published or updated this item on 03/15/2026.
QuantumBlack: A Global Force in Agentic AI Transformation
QuantumBlack: A Global Force in Agentic AI Transformation AI Magazine
QuantumBlack: A Global Force in Agentic AI Transformation matters because it signals momentum in agent and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent.
- Source context: AI Magazine published or updated this item on 03/16/2026.
Google AI Introduces Gemini Embedding 2: A Multimodal Embedding Model that Lets Your Bring Text, Images, Video, Audio, and Docs into the Embedding Space
Google AI Introduces Gemini Embedding 2: A Multimodal Embedding Model that Lets Your Bring Text, Images, Video, Audio, and Docs into the Embedding Space is one of the notable items tracked in today's digest.
Google AI Introduces Gemini Embedding 2: A Multimodal Embedding Model that Lets Your Bring Text, Images, Video, Audio, and Docs into the Embedding Space matters because it signals momentum in model, multimodal and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model, multimodal.
- Source context: Unknown source published or updated this item on 03/17/2026.
The ‘Bayesian’ Upgrade: Why Google AI’s New Teaching Method is the Key to LLM Reasoning
The ‘Bayesian’ Upgrade: Why Google AI’s New Teaching Method is the Key to LLM Reasoning MarkTechPost
The ‘Bayesian’ Upgrade: Why Google AI’s New Teaching Method is the Key to LLM Reasoning matters because it signals momentum in llm, reasoning and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: llm, reasoning.
- Source context: MarkTechPost published or updated this item on 03/09/2026.
Google AI Introduces Gemini Embedding 2: A Multimodal Embedding Model that Lets Your Bring Text, Images, Video, Audio, and Docs into the Embedding Space
Google AI Introduces Gemini Embedding 2: A Multimodal Embedding Model that Lets Your Bring Text, Images, Video, Audio, and Docs into the Embedding Space MarkTechPost
Google AI Introduces Gemini Embedding 2: A Multimodal Embedding Model that Lets Your Bring Text, Images, Video, Audio, and Docs into the Embedding Space matters because it signals momentum in model, multimodal and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model, multimodal.
- Source context: MarkTechPost published or updated this item on 03/11/2026.

How multi-agent AI economics influence business automation
Managing the economics of multi-agent AI now dictates the financial viability of modern business automation workflows. Organisations progressing past standard chat interfaces into multi-agent applications face two primary constraints. The first issue is the thinking tax;...
How multi-agent AI economics influence business automation matters because it signals momentum in agent, agents and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, agents.
- Source context: AI News published or updated this item on 03/12/2026.
Identifying Interactions at Scale for LLMs
Understanding the behavior of complex machine learning systems, particularly Large Language Models (LLMs), is a critical challenge in modern artificial intelligence. Interpretability research aims to make the decision-making process more transparent to model builders and...
Identifying Interactions at Scale for LLMs matters because it signals momentum in llm, model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: llm, model.
- Source context: BAIR Blog published or updated this item on 03/13/2026.
Deloitte: Why Business Agility is Central to AI Adoption
Deloitte: Why Business Agility is Central to AI Adoption AI Magazine
Deloitte: Why Business Agility is Central to AI Adoption matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: AI Magazine published or updated this item on 03/16/2026.
Measuring AI agent autonomy in practice
Measuring AI agent autonomy in practice Anthropic
Measuring AI agent autonomy in practice matters because it signals momentum in agent and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent.
- Source context: Anthropic Research published or updated this item on 02/18/2026.
The persona selection model
The persona selection model Anthropic
The persona selection model matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: Anthropic Research published or updated this item on 02/23/2026.
An update on our model deprecation commitments for Claude Opus 3
An update on our model deprecation commitments for Claude Opus 3 Anthropic
An update on our model deprecation commitments for Claude Opus 3 matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: Anthropic Research published or updated this item on 02/25/2026.
Top 10: LLM Fine Tuning Tools
Top 10: LLM Fine Tuning Tools AI Magazine
Top 10: LLM Fine Tuning Tools matters because it signals momentum in llm and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: llm.
- Source context: AI Magazine published or updated this item on 02/25/2026.
Bringing Robotics AI to Embedded Platforms: Dataset Recording, VLA Fine‑Tuning, and On‑Device Optimizations
A Blog post by NXP on Hugging Face
Bringing Robotics AI to Embedded Platforms: Dataset Recording, VLA Fine‑Tuning, and On‑Device Optimizations matters because it signals momentum in robotics and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: robotics.
- Source context: Hugging Face Blog published or updated this item on 03/05/2026.
Inside Reflection AI: The $20B Open-Model Startup That Has Yet to Ship
Inside Reflection AI: The $20B Open-Model Startup That Has Yet to Ship Turing Post
Inside Reflection AI: The $20B Open-Model Startup That Has Yet to Ship matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: Turing Post published or updated this item on 03/08/2026.

Ulysses Sequence Parallelism: Training with Million-Token Contexts
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Ulysses Sequence Parallelism: Training with Million-Token Contexts matters because it signals momentum in training and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: training.
- Source context: Hugging Face Blog published or updated this item on 03/09/2026.
An AI agent hacked McKinsey's internal AI platform in two hours using a decades-old technique
An AI agent hacked McKinsey's internal AI platform in two hours using a decades-old technique the-decoder.com
An AI agent hacked McKinsey's internal AI platform in two hours using a decades-old technique matters because it signals momentum in agent and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent.
- Source context: The Decoder published or updated this item on 03/11/2026.
Garry Tan Releases gstack: An Open-Source Claude Code System for Planning, Code Review, QA, and Shipping
Garry Tan Releases gstack: An Open-Source Claude Code System for Planning, Code Review, QA, and Shipping MarkTechPost
Garry Tan Releases gstack: An Open-Source Claude Code System for Planning, Code Review, QA, and Shipping matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: MarkTechPost published or updated this item on 03/14/2026.
AI 101: OpenClaw Explained + lightweight alternatives
AI 101: OpenClaw Explained + lightweight alternatives Turing Post
AI 101: OpenClaw Explained + lightweight alternatives matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Turing Post published or updated this item on 02/19/2026.
Anthropic Education Report: The AI Fluency Index
Anthropic Education Report: The AI Fluency Index Anthropic
Anthropic Education Report: The AI Fluency Index matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Anthropic Research published or updated this item on 02/23/2026.
AI Drug Discovery: How Roche Accelerates Health Innovation
AI Drug Discovery: How Roche Accelerates Health Innovation AI Magazine
AI Drug Discovery: How Roche Accelerates Health Innovation matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: AI Magazine published or updated this item on 02/26/2026.
Freeport-McMoRan Uses AI to Transform Mining Operations
Freeport-McMoRan Uses AI to Transform Mining Operations AI Magazine
Freeport-McMoRan Uses AI to Transform Mining Operations matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: AI Magazine published or updated this item on 02/26/2026.

Introducing Modular Diffusers - Composable Building Blocks for Diffusion Pipelines
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Introducing Modular Diffusers - Composable Building Blocks for Diffusion Pipelines matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Hugging Face Blog published or updated this item on 03/05/2026.
Labor market impacts of AI: A new measure and early evidence
Labor market impacts of AI: A new measure and early evidence Anthropic
Labor market impacts of AI: A new measure and early evidence matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Anthropic Research published or updated this item on 03/05/2026.
How Balyasny Asset Management built an AI research engine for investing
How Balyasny Asset Management built an AI research engine for investing OpenAI
How Balyasny Asset Management built an AI research engine for investing matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: OpenAI Research published or updated this item on 03/06/2026.
Is the Pentagon allowed to surveil Americans with AI?
Is the Pentagon allowed to surveil Americans with AI? MIT Technology Review
Is the Pentagon allowed to surveil Americans with AI? matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: MIT Tech Review AI published or updated this item on 03/06/2026.

Granite 4.0 1B Speech: Compact, Multilingual, and Built for the Edge
A Blog post by IBM Granite on Hugging Face
Granite 4.0 1B Speech: Compact, Multilingual, and Built for the Edge matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Hugging Face Blog published or updated this item on 03/09/2026.

LeRobot v0.5.0: Scaling Every Dimension
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
LeRobot v0.5.0: Scaling Every Dimension matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Hugging Face Blog published or updated this item on 03/09/2026.
OpenAI to acquire Promptfoo
OpenAI to acquire Promptfoo OpenAI
OpenAI to acquire Promptfoo matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: OpenAI Research published or updated this item on 03/09/2026.
FOD#143: What is Superhuman Adaptable Intelligence (SAI)?
FOD#143: What is Superhuman Adaptable Intelligence (SAI)? Turing Post
FOD#143: What is Superhuman Adaptable Intelligence (SAI)? matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Turing Post published or updated this item on 03/10/2026.
How Pokémon Go is giving delivery robots an inch-perfect view of the world
How Pokémon Go is giving delivery robots an inch-perfect view of the world MIT Technology Review
How Pokémon Go is giving delivery robots an inch-perfect view of the world matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: MIT Tech Review AI published or updated this item on 03/10/2026.

Introducing Storage Buckets on the Hugging Face Hub
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Introducing Storage Buckets on the Hugging Face Hub matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Hugging Face Blog published or updated this item on 03/10/2026.

Keep the Tokens Flowing: Lessons from 16 Open-Source RL Libraries
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Keep the Tokens Flowing: Lessons from 16 Open-Source RL Libraries matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Hugging Face Blog published or updated this item on 03/10/2026.
Startup claims first full brain emulation of a fruit fly in a simulated body
Startup claims first full brain emulation of a fruit fly in a simulated body the-decoder.com
Startup claims first full brain emulation of a fruit fly in a simulated body matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: The Decoder published or updated this item on 03/10/2026.

E.SUN Bank and IBM build AI governance framework for banking
E.SUN Bank is working with IBM to build clearer AI governance rules for how artificial intelligence can be used inside a bank. The effort reflects a wider shift in finance. Many firms already use AI for fraud checks and credit scoring, and some also use it to handle customer...
E.SUN Bank and IBM build AI governance framework for banking matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: AI News published or updated this item on 03/13/2026.
Why physical AI is becoming manufacturing’s next advantage
Why physical AI is becoming manufacturing’s next advantage MIT Technology Review
Why physical AI is becoming manufacturing’s next advantage matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: MIT Tech Review AI published or updated this item on 03/13/2026.
From model to agent: Equipping the Responses API with a computer environment
From model to agent: Equipping the Responses API with a computer environment OpenAI
From model to agent: Equipping the Responses API with a computer environment matters because it affects the policy, supply-chain, or security constraints around AI development, especially across compute, agent, model.
- Primary signals: compute, agent, model.
- Source context: OpenAI Research published or updated this item on 03/11/2026.
US Treasury publishes AI risk Guidebook for financial institutions
The US Treasury has published several documents designed for the US financial services sector that suggest a structured approach to managing AI risks in operations and policy (see subheading ‘Resources and Downloads’ towards the bottom of the link). The CRI Financial Services...
US Treasury publishes AI risk Guidebook for financial institutions matters because it affects the policy, supply-chain, or security constraints around AI development, especially across policy.
- Primary signals: policy.
- Source context: AI News published or updated this item on 03/16/2026.
A defense official reveals how AI chatbots could be used for targeting decisions
A defense official reveals how AI chatbots could be used for targeting decisions MIT Technology Review
A defense official reveals how AI chatbots could be used for targeting decisions matters because it affects the policy, supply-chain, or security constraints around AI development, especially across defense, chatbot.
- Primary signals: defense, chatbot.
- Source context: MIT Tech Review AI published or updated this item on 03/12/2026.
BMW puts humanoid robots to work in Germany–and Europe’s factories are watching
Europe’s factory floors have a new kind of colleague. BMW Group has deployed humanoid robots in manufacturing in Germany for the first time, launching a pilot project at its Leipzig plant with AEON–a wheeled humanoid built by Hexagon Robotics. It is the first automotive...
BMW puts humanoid robots to work in Germany–and Europe’s factories are watching matters because it affects the policy, supply-chain, or security constraints around AI development, especially across europe, robotics.
- Primary signals: europe, robotics.
- Source context: AI News published or updated this item on 03/13/2026.
AI Can Learn Scientific Taste
TL;DR: Great scientists have strong judgement and foresight, closely tied to what we call scientific taste.
Great scientists have strong judgement and foresight, closely tied to what we call scientific taste. Here, we use the term to refer to the capacity to judge and propose research ideas with high potential impact. However, most relative research focuses on improving an AI...
In this work, we propose Reinforcement Learning from Community Feedback (RLCF), a training paradigm that uses large-scale community signals as supervision, and formulate scientific taste learning as a preference modeling and alignment problem.
In this work, we propose Reinforcement Learning from Community Feedback (RLCF), a training paradigm that uses large-scale community signals as supervision, and formulate scientific taste learning as a preference modeling and alignment problem.
Experiments show Scientific Judge outperforms SOTA LLMs (e.g., GPT-5.2, Gemini 3 Pro) and generalizes to future-year test, unseen fields, and peer-review preference.
The reported improvement still needs a closer check on benchmark scope, ablations, and whether the method keeps working outside the authors' evaluation setup.
- Problem framing: In this work, we propose Reinforcement Learning from Community Feedback (RLCF), a training paradigm that uses large-scale community signals as supervision, and formulate scientific taste learning as a preference modeling and alignment problem.
- Method signal: In this work, we propose Reinforcement Learning from Community Feedback (RLCF), a training paradigm that uses large-scale community signals as supervision, and formulate scientific taste learning as a preference modeling and alignment problem.
- Evidence to watch: Experiments show Scientific Judge outperforms SOTA LLMs (e.g., GPT-5.2, Gemini 3 Pro) and generalizes to future-year test, unseen fields, and peer-review preference.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: In this work, we propose Reinforcement Learning from Community Feedback (RLCF), a training paradigm that uses large-scale community signals as supervision, and formulate scientific taste learning as a...
- Approach: In this work, we propose Reinforcement Learning from Community Feedback (RLCF), a training paradigm that uses large-scale community signals as supervision, and formulate scientific taste learning as a...
- Result signal: Experiments show Scientific Judge outperforms SOTA LLMs (e.g., GPT-5.2, Gemini 3 Pro) and generalizes to future-year test, unseen fields, and peer-review preference.
- Community traction: Hugging Face Papers shows 58 votes for this paper.
- The reported improvement still needs a closer check on benchmark scope, ablations, and whether the method keeps working outside the authors' evaluation setup.
OpenSeeker: Democratizing Frontier Search Agents by Fully Open-Sourcing Training Data
TL;DR: Deep search capabilities have become an indispensable competency for frontier Large Language Model (LLM) agents, yet the development of high-performance search agents remains dominated by industrial giants due to a...
Deep search capabilities have become an indispensable competency for frontier Large Language Model (LLM) agents, yet the development of high-performance search agents remains dominated by industrial giants due to a lack of transparent, high-quality training data. This...
To bridge this gap, we introduce OpenSeeker, the first fully open-source search agent (i.e., model and data) that achieves frontier-level performance through two core technical innovations: (1) Fact-grounded scalable controllable QA synthesis, which...
To bridge this gap, we introduce OpenSeeker, the first fully open-source search agent (i.e., model and data) that achieves frontier-level performance through two core technical innovations: (1) Fact-grounded scalable controllable QA synthesis, which reverse-engineers the web graph via topological expansion and...
Deep search capabilities have become an indispensable competency for frontier Large Language Model (LLM) agents, yet the development of high-performance search agents remains dominated by industrial giants due to a lack of transparent, high-quality training data.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: To bridge this gap, we introduce OpenSeeker, the first fully open-source search agent (i.e., model and data) that achieves frontier-level performance through two core technical innovations: (1) Fact-grounded scalable controllable QA...
- Method signal: To bridge this gap, we introduce OpenSeeker, the first fully open-source search agent (i.e., model and data) that achieves frontier-level performance through two core technical innovations: (1) Fact-grounded scalable controllable QA...
- Evidence to watch: Deep search capabilities have become an indispensable competency for frontier Large Language Model (LLM) agents, yet the development of high-performance search agents remains dominated by industrial giants due to a lack of transparent,...
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: To bridge this gap, we introduce OpenSeeker, the first fully open-source search agent (i.e., model and data) that achieves frontier-level performance through two core technical innovations: (1) Fact-grounded...
- Approach: To bridge this gap, we introduce OpenSeeker, the first fully open-source search agent (i.e., model and data) that achieves frontier-level performance through two core technical innovations: (1)...
- Result signal: Deep search capabilities have become an indispensable competency for frontier Large Language Model (LLM) agents, yet the development of high-performance search agents remains dominated by industrial...
- Community traction: Hugging Face Papers shows 74 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
Grounding World Simulation Models in a Real-World Metropolis
TL;DR: What if a world simulation model could render not an imagined environment but a city that actually exists?
What if a world simulation model could render not an imagined environment but a city that actually exists? Prior generative world models synthesize visually plausible yet artificial environments by imagining all content. We present Seoul World Model (SWM), a city-scale world...
However, this design introduces several challenges, including temporal misalignment between retrieved references and the dynamic target scene, limited trajectory diversity and data sparsity from vehicle-mounted captures at sparse intervals.
We present Seoul World Model (SWM), a city-scale world model grounded in the real city of Seoul.
SWM outperforms existing methods in generating spatially faithful, temporally consistent, long-horizon videos grounded in actual urban environments over trajectories reaching hundreds of meters, while supporting diverse camera movements and text-prompted scenario variations.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: However, this design introduces several challenges, including temporal misalignment between retrieved references and the dynamic target scene, limited trajectory diversity and data sparsity from vehicle-mounted captures at sparse intervals.
- Method signal: We present Seoul World Model (SWM), a city-scale world model grounded in the real city of Seoul.
- Evidence to watch: SWM outperforms existing methods in generating spatially faithful, temporally consistent, long-horizon videos grounded in actual urban environments over trajectories reaching hundreds of meters, while supporting diverse camera movements...
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: However, this design introduces several challenges, including temporal misalignment between retrieved references and the dynamic target scene, limited trajectory diversity and data sparsity from...
- Approach: We present Seoul World Model (SWM), a city-scale world model grounded in the real city of Seoul.
- Result signal: SWM outperforms existing methods in generating spatially faithful, temporally consistent, long-horizon videos grounded in actual urban environments over trajectories reaching hundreds of meters, while...
- Community traction: Hugging Face Papers shows 63 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
HSImul3R: Physics-in-the-Loop Reconstruction of Simulation-Ready Human-Scene Interactions
TL;DR: HSImul3R presents a unified framework for 3D reconstruction of human-scene interactions that bridges the perception-simulation gap through physics-grounded bidirectional optimization and reinforcement learning.
HSImul3R presents a unified framework for 3D reconstruction of human-scene interactions that bridges the perception-simulation gap through physics-grounded bidirectional optimization and reinforcement learning. We present HSImul3R, a unified framework for simulation-ready 3D...
HSImul3R presents a unified framework for 3D reconstruction of human-scene interactions that bridges the perception-simulation gap through physics-grounded bidirectional optimization and reinforcement learning.
We present HSImul3R, a unified framework for simulation-ready 3D reconstruction of human-scene interactions (HSI) from casual captures, including sparse-view images and monocular videos.
Extensive experiments demonstrate that HSImul3R produces the first stable, simulation-ready HSI reconstructions and can be directly deployed to real-world humanoid robots .
The reported improvement still needs a closer check on benchmark scope, ablations, and whether the method keeps working outside the authors' evaluation setup.
- Problem framing: HSImul3R presents a unified framework for 3D reconstruction of human-scene interactions that bridges the perception-simulation gap through physics-grounded bidirectional optimization and reinforcement learning.
- Method signal: We present HSImul3R, a unified framework for simulation-ready 3D reconstruction of human-scene interactions (HSI) from casual captures, including sparse-view images and monocular videos.
- Evidence to watch: Extensive experiments demonstrate that HSImul3R produces the first stable, simulation-ready HSI reconstructions and can be directly deployed to real-world humanoid robots .
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: HSImul3R presents a unified framework for 3D reconstruction of human-scene interactions that bridges the perception-simulation gap through physics-grounded bidirectional optimization and reinforcement learning.
- Approach: We present HSImul3R, a unified framework for simulation-ready 3D reconstruction of human-scene interactions (HSI) from casual captures, including sparse-view images and monocular videos.
- Result signal: Extensive experiments demonstrate that HSImul3R produces the first stable, simulation-ready HSI reconstructions and can be directly deployed to real-world humanoid robots .
- Community traction: Hugging Face Papers shows 17 votes for this paper.
- The reported improvement still needs a closer check on benchmark scope, ablations, and whether the method keeps working outside the authors' evaluation setup.
ViFeEdit: A Video-Free Tuner of Your Video Diffusion Transformer
TL;DR: Diffusion Transformers (DiTs) have demonstrated remarkable scalability and quality in image and video generation, prompting growing interest in extending them to controllable generation and editing tasks.
Diffusion Transformers (DiTs) have demonstrated remarkable scalability and quality in image and video generation, prompting growing interest in extending them to controllable generation and editing tasks. However, compared to the image counterparts, progress in video control...
Diffusion Transformers (DiTs) have demonstrated remarkable scalability and quality in image and video generation, prompting growing interest in extending them to controllable generation and editing tasks.
To address this issue, in this paper, we propose a video-free tuning framework termed ViFeEdit for video diffusion transformers.
Diffusion Transformers (DiTs) have demonstrated remarkable scalability and quality in image and video generation, prompting growing interest in extending them to controllable generation and editing tasks.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: Diffusion Transformers (DiTs) have demonstrated remarkable scalability and quality in image and video generation, prompting growing interest in extending them to controllable generation and editing tasks.
- Method signal: To address this issue, in this paper, we propose a video-free tuning framework termed ViFeEdit for video diffusion transformers.
- Evidence to watch: Diffusion Transformers (DiTs) have demonstrated remarkable scalability and quality in image and video generation, prompting growing interest in extending them to controllable generation and editing tasks.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: Diffusion Transformers (DiTs) have demonstrated remarkable scalability and quality in image and video generation, prompting growing interest in extending them to controllable generation and editing tasks.
- Approach: To address this issue, in this paper, we propose a video-free tuning framework termed ViFeEdit for video diffusion transformers.
- Result signal: Diffusion Transformers (DiTs) have demonstrated remarkable scalability and quality in image and video generation, prompting growing interest in extending them to controllable generation and editing tasks.
- Community traction: Hugging Face Papers shows 14 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
Issue routing and exits.
The daily edition stays aligned with the rest of the site while keeping the full issue readable end to end.
Navigation
Public desks
Issue
- 03/17/2026
- 52 total analyzed
- Readable issue route