Daily Edition
The expanded edition keeps the full analyst notes, paper breakdowns, geopolitical framing, and the complete feed selected into this run.
Topic of the day.
A dedicated daily topic chosen from the strongest signals in the run, with TL;DR, why-now framing, and a fuller analyst read.
AI policy, power, and industrial competition
TL;DR: AI policy, power, and industrial competition is today's clearest AI theme: LWiAI Podcast #237 - Nemotron 3 Super, xAI reborn, Anthropic Lawsuit, Research! leads the signal, and related coverage suggests the shift is moving from isolated...
Why now: The topic shows up across Last Week in AI and AI News, AI Magazine, which means the same operating pressure is appearing through multiple lenses instead of only one announcement.
AI policy, power, and industrial competition deserves the slower read today because the supporting items cluster around defense, agent, reasoning. LWiAI Podcast #237 - Nemotron 3 Super, xAI reborn, Anthropic Lawsuit, Research! matters because it affects the policy, supply-chain, or security constraints around AI development, especially across defense, agent, reasoning. The combined signal suggests teams should treat this as a real operating change rather than background noise.
- Last Week in AI: LWiAI Podcast #237 - Nemotron 3 Super, xAI reborn, Anthropic Lawsuit, Research! points to LWiAI Podcast #237 - Nemotron 3 Super, xAI reborn, Anthropic Lawsuit, Research! matters because it affects...
- AI News: 5 best practices to secure AI systems points to 5 best practices to secure AI systems matters because it affects the policy, supply-chain, or security constraints around AI development, especially across...
- AI Magazine: Novee Introduces Autonomous AI Red Teaming to Uncover Security Flaws in LLM Applications points to Novee Introduces Autonomous AI Red Teaming to Uncover Security Flaws in LLM Applications matters because...
- LWiAI Podcast #237 - Nemotron 3 Super, xAI reborn, Anthropic Lawsuit, Research! (Last Week in AI | 2026-03-16)
- 5 best practices to secure AI systems (AI News | 2026-04-02)
- Novee Introduces Autonomous AI Red Teaming to Uncover Security Flaws in LLM Applications (AI Magazine | 2026-03-25)
Policy, chips, capital, and power.
Industrial strategy, compute supply, export controls, and big-company positioning shaping the AI balance of power.
LWiAI Podcast #237 - Nemotron 3 Super, xAI reborn, Anthropic Lawsuit, Research!
Nemotron 3 Super: An Open Hybrid Mamba-Transformer MoE for Agentic Reasoning, Another XAI Cofounder Has Left, Anthropic Sues Department of Defense
LWiAI Podcast #237 - Nemotron 3 Super, xAI reborn, Anthropic Lawsuit, Research! matters because it affects the policy, supply-chain, or security constraints around AI development, especially across defense, agent, reasoning.
- Primary signals: defense, agent, reasoning.
- Source context: Last Week in AI published or updated this item on 2026-03-16.

5 best practices to secure AI systems
A decade ago, it would have been hard to believe that artificial intelligence could do what it can do now. However, it is this same power that introduces a new attack surface that traditional security frameworks were not built to address. As this technology becomes embedded...
5 best practices to secure AI systems matters because it affects the policy, supply-chain, or security constraints around AI development, especially across defense, security.
- Primary signals: defense, security.
- Source context: AI News published or updated this item on 2026-04-02.
Novee Introduces Autonomous AI Red Teaming to Uncover Security Flaws in LLM Applications
Novee Introduces Autonomous AI Red Teaming to Uncover Security Flaws in LLM Applications AI Magazine
Novee Introduces Autonomous AI Red Teaming to Uncover Security Flaws in LLM Applications matters because it affects the policy, supply-chain, or security constraints around AI development, especially across security, llm.
- Primary signals: security, llm.
- Source context: AI Magazine published or updated this item on 2026-03-25.

Holo3: Breaking the Computer Use Frontier
A Blog post by H company on Hugging Face
Holo3: Breaking the Computer Use Frontier matters because it affects the policy, supply-chain, or security constraints around AI development, especially across compute, frontier.
- Primary signals: compute, frontier.
- Source context: Hugging Face Blog published or updated this item on 2026-04-01.

DeepL’s Borderless Business report reveals 83% of enterprises are still behind on language AI
AI is everywhere in the enterprise. The translation workflow often is not. That is the core finding of DeepL’s 2026 Language AI report, “Borderless Business: Transforming Translation in the Age of AI,” published on March 10. Despite broad AI investment across business...
DeepL’s Borderless Business report reveals 83% of enterprises are still behind on language AI matters because it affects the policy, supply-chain, or security constraints around AI development, especially across border.
- Primary signals: border.
- Source context: AI News published or updated this item on 2026-04-01.
Product, model, and platform movement.
Software, model, deployment, and competitive stories with the strongest operator and market signal in this edition.
9 Open Agents That Improve Themselves
9 Open Agents That Improve Themselves turingpost.com
9 Open Agents That Improve Themselves matters because it signals momentum in agent, agents and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, agents.
- Source context: Turing Post published or updated this item on 2026-04-05.

Gemma 4: Byte for byte, the most capable open models
Gemma 4: Our most intelligent open models to date, purpose-built for advanced reasoning and agentic workflows.
Gemma 4: Byte for byte, the most capable open models matters because it signals momentum in agent, model, reasoning and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, model, reasoning.
- Source context: DeepMind Blog published or updated this item on 2026-04-02.

KiloClaw targets shadow AI with autonomous agent governance
With the launch of KiloClaw, enterprises now have a tool to enforce governance over autonomous agents and manage shadow AI. While businesses spent the last year securing large language models and formalising vendor agreements, developers and knowledge workers started moving...
KiloClaw targets shadow AI with autonomous agent governance matters because it signals momentum in agent, agents, model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, agents, model.
- Source context: AI News published or updated this item on 2026-04-02.
Meet ‘AutoAgent’: The Open-Source Library That Lets an AI Engineer and Optimize Its Own Agent Harness Overnight
Meet ‘AutoAgent’: The Open-Source Library That Lets an AI Engineer and Optimize Its Own Agent Harness Overnight MarkTechPost
Meet ‘AutoAgent’: The Open-Source Library That Lets an AI Engineer and Optimize Its Own Agent Harness Overnight matters because it signals momentum in agent and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent.
- Source context: MarkTechPost published or updated this item on 2026-04-05.

A New Framework for Evaluating Voice Agents (EVA)
A Blog post by ServiceNow-AI on Hugging Face
A New Framework for Evaluating Voice Agents (EVA) matters because it signals momentum in agent, agents and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, agents.
- Source context: Hugging Face Blog published or updated this item on 2026-03-24.
Differentiated source coverage.
Stories drawn from research blogs, first-party lab posts, practitioner newsletters, and selected technical outlets so the edition does not mirror the same headline across every source.

Welcome Gemma 4: Frontier multimodal intelligence on device
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Welcome Gemma 4: Frontier multimodal intelligence on device matters because it signals momentum in frontier, multimodal and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: frontier, multimodal.
- Source context: Hugging Face Blog published or updated this item on 2026-04-02.
OpenAI Model Craft: Parameter Golf
OpenAI Model Craft: Parameter Golf OpenAI
OpenAI Model Craft: Parameter Golf matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: OpenAI Research published or updated this item on 2026-03-18.
A “diff” tool for AI: Finding behavioral differences in new models
A “diff” tool for AI: Finding behavioral differences in new models Anthropic
A “diff” tool for AI: Finding behavioral differences in new models matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: Anthropic Research published or updated this item on 2026-03-13.

Protecting people from harmful manipulation
Google DeepMind researches AI's harmful manipulation risks across areas like finance and health, leading to new safety measures.
Protecting people from harmful manipulation matters because it signals momentum in safety and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: safety.
- Source context: DeepMind Blog published or updated this item on 2026-03-25.
How to Build Production-Ready Agentic Systems with Z.AI GLM-5 Using Thinking Mode, Tool Calling, Streaming, and Multi-Turn Workflows
How to Build Production-Ready Agentic Systems with Z.AI GLM-5 Using Thinking Mode, Tool Calling, Streaming, and Multi-Turn Workflows MarkTechPost
How to Build Production-Ready Agentic Systems with Z.AI GLM-5 Using Thinking Mode, Tool Calling, Streaming, and Multi-Turn Workflows matters because it signals momentum in agent and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent.
- Source context: MarkTechPost published or updated this item on 2026-04-04.

China’s Five-Year Plan details the targets for AI deployment
China has approved its 15th Five-Year Plan [PDF] setting out the country’s economic, education, social, and industrial priorities through to 2030. As might be expected, there is a significant number of references to AI, with the technology mentioned in several contexts. AI is...
China’s Five-Year Plan details the targets for AI deployment matters because it affects the policy, supply-chain, or security constraints around AI development, especially across china.
- Primary signals: china.
- Source context: AI News published or updated this item on 2026-04-02.
QuantumBlack: A Global Force in Agentic AI Transformation
QuantumBlack: A Global Force in Agentic AI Transformation AI Magazine
QuantumBlack: A Global Force in Agentic AI Transformation matters because it signals momentum in agent and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent.
- Source context: AI Magazine published or updated this item on 2026-03-16.
AI benchmarks are broken. Here’s what we need instead.
AI benchmarks are broken. Here’s what we need instead. MIT Technology Review
AI benchmarks are broken. Here’s what we need instead. matters because it signals momentum in benchmark and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: benchmark.
- Source context: MIT Tech Review AI published or updated this item on 2026-03-31.
Method, limitations, and results.
Paper summaries, methodology notes, limitations, and deep-dive bullets for the research items selected into the digest.

Agentic-MME: What Agentic Capability Really Brings to Multimodal Intelligence?
TL;DR: A new benchmark evaluates multimodal agentic capabilities by verifying tool usage and process efficiency rather than just final answers, revealing significant challenges in real-world multimodal problem-solving.
A new benchmark evaluates multimodal agentic capabilities by verifying tool usage and process efficiency rather than just final answers, revealing significant challenges in real-world multimodal problem-solving. Multimodal Large Language Models (MLLMs) are evolving from...
A new benchmark evaluates multimodal agentic capabilities by verifying tool usage and process efficiency rather than just final answers, revealing significant challenges in real-world multimodal problem-solving.
To address this, we introduce Agentic-MME , a process-verified benchmark for Multimodal Agentic Capabilities.
A new benchmark evaluates multimodal agentic capabilities by verifying tool usage and process efficiency rather than just final answers, revealing significant challenges in real-world multimodal problem-solving.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: A new benchmark evaluates multimodal agentic capabilities by verifying tool usage and process efficiency rather than just final answers, revealing significant challenges in real-world multimodal problem-solving.
- Method signal: To address this, we introduce Agentic-MME , a process-verified benchmark for Multimodal Agentic Capabilities.
- Evidence to watch: A new benchmark evaluates multimodal agentic capabilities by verifying tool usage and process efficiency rather than just final answers, revealing significant challenges in real-world multimodal problem-solving.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: A new benchmark evaluates multimodal agentic capabilities by verifying tool usage and process efficiency rather than just final answers, revealing significant challenges in real-world multimodal problem-solving.
- Approach: To address this, we introduce Agentic-MME , a process-verified benchmark for Multimodal Agentic Capabilities.
- Result signal: A new benchmark evaluates multimodal agentic capabilities by verifying tool usage and process efficiency rather than just final answers, revealing significant challenges in real-world multimodal...
- Community traction: Hugging Face Papers shows 15 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.

Token Warping Helps MLLMs Look from Nearby Viewpoints
TL;DR: Token-level warping in vision-language models demonstrates superior stability and semantic coherence for viewpoint transformation compared to pixel-wise methods, achieving better visual reasoning performance.
Token-level warping in vision-language models demonstrates superior stability and semantic coherence for viewpoint transformation compared to pixel-wise methods, achieving better visual reasoning performance. Can warping tokens , rather than pixels, help multimodal large...
Token-level warping in vision-language models demonstrates superior stability and semantic coherence for viewpoint transformation compared to pixel-wise methods, achieving better visual reasoning performance.
Can warping tokens , rather than pixels, help multimodal large language models (MLLMs) understand how a scene appears from a nearby viewpoint?
Token-level warping in vision-language models demonstrates superior stability and semantic coherence for viewpoint transformation compared to pixel-wise methods, achieving better visual reasoning performance.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: Token-level warping in vision-language models demonstrates superior stability and semantic coherence for viewpoint transformation compared to pixel-wise methods, achieving better visual reasoning performance.
- Method signal: Can warping tokens , rather than pixels, help multimodal large language models (MLLMs) understand how a scene appears from a nearby viewpoint?
- Evidence to watch: Token-level warping in vision-language models demonstrates superior stability and semantic coherence for viewpoint transformation compared to pixel-wise methods, achieving better visual reasoning performance.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: Token-level warping in vision-language models demonstrates superior stability and semantic coherence for viewpoint transformation compared to pixel-wise methods, achieving better visual reasoning performance.
- Approach: Can warping tokens , rather than pixels, help multimodal large language models (MLLMs) understand how a scene appears from a nearby viewpoint?
- Result signal: Token-level warping in vision-language models demonstrates superior stability and semantic coherence for viewpoint transformation compared to pixel-wise methods, achieving better visual reasoning...
- Community traction: Hugging Face Papers shows 15 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.

Xpertbench: Expert Level Tasks with Rubrics-Based Evaluation
TL;DR: XpertBench presents a comprehensive benchmark for evaluating large language models across professional domains using expert-curated tasks and a novel LLM-based evaluation approach called ShotJudge.
XpertBench presents a comprehensive benchmark for evaluating large language models across professional domains using expert-curated tasks and a novel LLM-based evaluation approach called ShotJudge. As Large Language Models (LLMs) exhibit plateauing performance on conventional...
XpertBench presents a comprehensive benchmark for evaluating large language models across professional domains using expert-curated tasks and a novel LLM-based evaluation approach called ShotJudge.
To bridge this gap, we present XpertBench , a high-fidelity benchmark engineered to assess LLMs across authentic professional domains .
As Large Language Models (LLMs) exhibit plateauing performance on conventional benchmarks, a pivotal challenge persists: evaluating their proficiency in complex, open-ended tasks characterizing genuine expert-level cognition .
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: XpertBench presents a comprehensive benchmark for evaluating large language models across professional domains using expert-curated tasks and a novel LLM-based evaluation approach called ShotJudge.
- Method signal: To bridge this gap, we present XpertBench , a high-fidelity benchmark engineered to assess LLMs across authentic professional domains .
- Evidence to watch: As Large Language Models (LLMs) exhibit plateauing performance on conventional benchmarks, a pivotal challenge persists: evaluating their proficiency in complex, open-ended tasks characterizing genuine expert-level cognition .
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: XpertBench presents a comprehensive benchmark for evaluating large language models across professional domains using expert-curated tasks and a novel LLM-based evaluation approach called ShotJudge.
- Approach: To bridge this gap, we present XpertBench , a high-fidelity benchmark engineered to assess LLMs across authentic professional domains .
- Result signal: As Large Language Models (LLMs) exhibit plateauing performance on conventional benchmarks, a pivotal challenge persists: evaluating their proficiency in complex, open-ended tasks characterizing genuine...
- Community traction: Hugging Face Papers shows 2 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
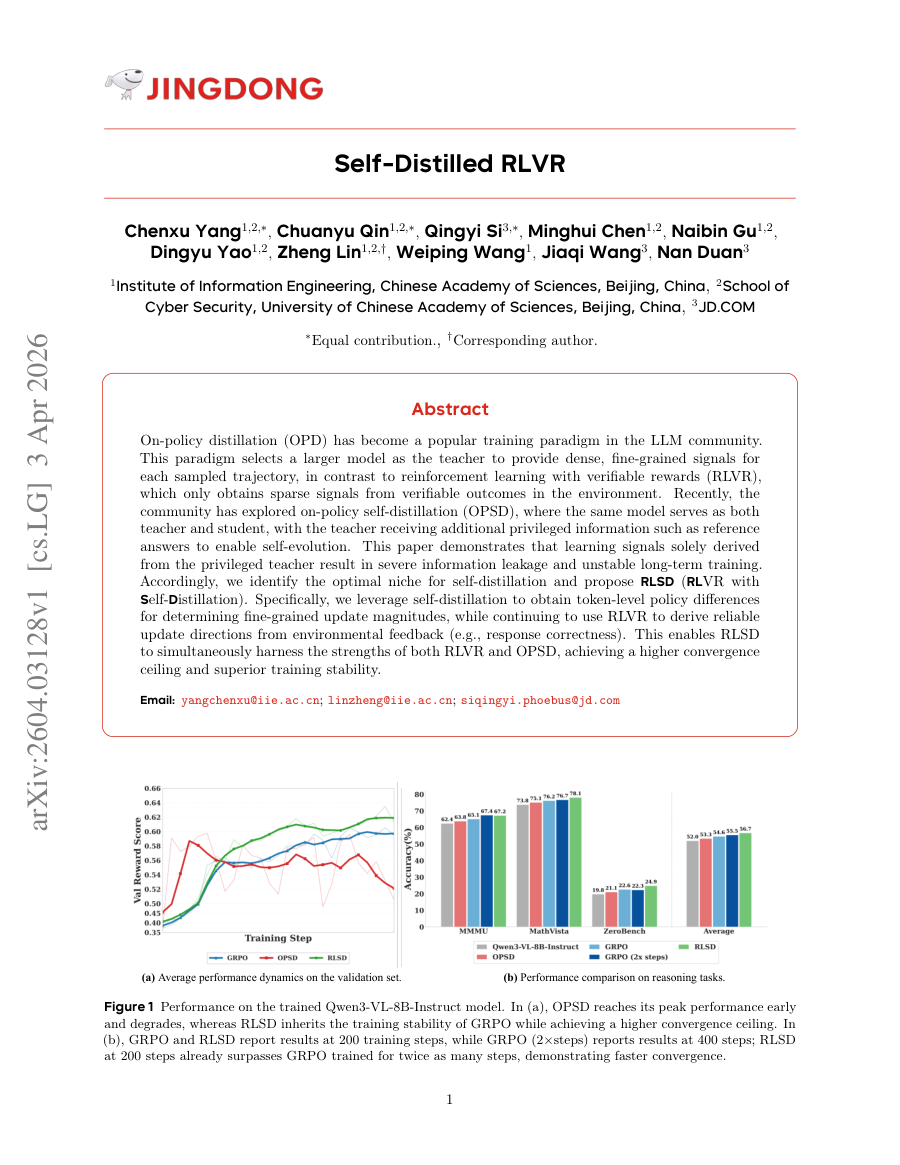
Self-Distilled RLVR
TL;DR: RLSD combines reinforcement learning with verifiable rewards and self-distillation to achieve stable training with fine-grained updates and reliable policy direction from environmental feedback.
RLSD combines reinforcement learning with verifiable rewards and self-distillation to achieve stable training with fine-grained updates and reliable policy direction from environmental feedback. On-policy distillation (OPD) has become a popular training paradigm in the LLM...
RLSD combines reinforcement learning with verifiable rewards and self-distillation to achieve stable training with fine-grained updates and reliable policy direction from environmental feedback.
This paper demonstrates that learning signals solely derived from the privileged teacher result in severe information leakage and unstable long-term training.
RLSD combines reinforcement learning with verifiable rewards and self-distillation to achieve stable training with fine-grained updates and reliable policy direction from environmental feedback.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: RLSD combines reinforcement learning with verifiable rewards and self-distillation to achieve stable training with fine-grained updates and reliable policy direction from environmental feedback.
- Method signal: This paper demonstrates that learning signals solely derived from the privileged teacher result in severe information leakage and unstable long-term training.
- Evidence to watch: RLSD combines reinforcement learning with verifiable rewards and self-distillation to achieve stable training with fine-grained updates and reliable policy direction from environmental feedback.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: RLSD combines reinforcement learning with verifiable rewards and self-distillation to achieve stable training with fine-grained updates and reliable policy direction from environmental feedback.
- Approach: This paper demonstrates that learning signals solely derived from the privileged teacher result in severe information leakage and unstable long-term training.
- Result signal: RLSD combines reinforcement learning with verifiable rewards and self-distillation to achieve stable training with fine-grained updates and reliable policy direction from environmental feedback.
- Community traction: Hugging Face Papers shows 10 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.

A Simple Baseline for Streaming Video Understanding
TL;DR: A simple sliding-window approach using recent video frames outperforms complex memory-based streaming video understanding methods, revealing trade-offs between real-time perception and long-term memory capabilities.
A simple sliding-window approach using recent video frames outperforms complex memory-based streaming video understanding methods, revealing trade-offs between real-time perception and long-term memory capabilities. Recent streaming video understanding methods increasingly...
We challenge this trend with a simple finding: a sliding-window baseline that feeds only the most recent N frames to an off-the-shelf VLM already matches or surpasses published streaming models.
Recent streaming video understanding methods increasingly rely on complex memory mechanisms to handle long video streams.
A simple sliding-window approach using recent video frames outperforms complex memory-based streaming video understanding methods, revealing trade-offs between real-time perception and long-term memory capabilities.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: We challenge this trend with a simple finding: a sliding-window baseline that feeds only the most recent N frames to an off-the-shelf VLM already matches or surpasses published streaming models.
- Method signal: Recent streaming video understanding methods increasingly rely on complex memory mechanisms to handle long video streams.
- Evidence to watch: A simple sliding-window approach using recent video frames outperforms complex memory-based streaming video understanding methods, revealing trade-offs between real-time perception and long-term memory capabilities.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: We challenge this trend with a simple finding: a sliding-window baseline that feeds only the most recent N frames to an off-the-shelf VLM already matches or surpasses published streaming models.
- Approach: Recent streaming video understanding methods increasingly rely on complex memory mechanisms to handle long video streams.
- Result signal: A simple sliding-window approach using recent video frames outperforms complex memory-based streaming video understanding methods, revealing trade-offs between real-time perception and long-term memory...
- Community traction: Hugging Face Papers shows 26 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
Everything selected into the run.
The complete analyzed stream for the issue, useful when you want to scan the entire run instead of only the curated front page.
9 Open Agents That Improve Themselves
9 Open Agents That Improve Themselves turingpost.com
9 Open Agents That Improve Themselves matters because it signals momentum in agent, agents and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, agents.
- Source context: Turing Post published or updated this item on 2026-04-05.
Gemma 4: Byte for byte, the most capable open models
Gemma 4: Our most intelligent open models to date, purpose-built for advanced reasoning and agentic workflows.
Gemma 4: Byte for byte, the most capable open models matters because it signals momentum in agent, model, reasoning and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, model, reasoning.
- Source context: DeepMind Blog published or updated this item on 2026-04-02.
KiloClaw targets shadow AI with autonomous agent governance
With the launch of KiloClaw, enterprises now have a tool to enforce governance over autonomous agents and manage shadow AI. While businesses spent the last year securing large language models and formalising vendor agreements, developers and knowledge workers started moving...
KiloClaw targets shadow AI with autonomous agent governance matters because it signals momentum in agent, agents, model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, agents, model.
- Source context: AI News published or updated this item on 2026-04-02.
Meet ‘AutoAgent’: The Open-Source Library That Lets an AI Engineer and Optimize Its Own Agent Harness Overnight
Meet ‘AutoAgent’: The Open-Source Library That Lets an AI Engineer and Optimize Its Own Agent Harness Overnight MarkTechPost
Meet ‘AutoAgent’: The Open-Source Library That Lets an AI Engineer and Optimize Its Own Agent Harness Overnight matters because it signals momentum in agent and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent.
- Source context: MarkTechPost published or updated this item on 2026-04-05.
A New Framework for Evaluating Voice Agents (EVA)
A Blog post by ServiceNow-AI on Hugging Face
A New Framework for Evaluating Voice Agents (EVA) matters because it signals momentum in agent, agents and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, agents.
- Source context: Hugging Face Blog published or updated this item on 2026-03-24.

Autonomous AI systems depend on data governance
Much of the current focus on AI safety has centred on models – how they are trained and monitored. But as systems become more autonomous, attention is changing toward the data those systems depend on. If the data feeding an AI system is fragmented, outdated, or lacks...
Autonomous AI systems depend on data governance matters because it signals momentum in model, safety and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model, safety.
- Source context: AI News published or updated this item on 2026-04-02.
Welcome Gemma 4: Frontier multimodal intelligence on device
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Welcome Gemma 4: Frontier multimodal intelligence on device matters because it signals momentum in frontier, multimodal and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: frontier, multimodal.
- Source context: Hugging Face Blog published or updated this item on 2026-04-02.
How to Build Production-Ready Agentic Systems with Z.AI GLM-5 Using Thinking Mode, Tool Calling, Streaming, and Multi-Turn Workflows
How to Build Production-Ready Agentic Systems with Z.AI GLM-5 Using Thinking Mode, Tool Calling, Streaming, and Multi-Turn Workflows MarkTechPost
How to Build Production-Ready Agentic Systems with Z.AI GLM-5 Using Thinking Mode, Tool Calling, Streaming, and Multi-Turn Workflows matters because it signals momentum in agent and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent.
- Source context: MarkTechPost published or updated this item on 2026-04-04.
Netflix AI Team Just Open-Sourced VOID: an AI Model That Erases Objects From Videos — Physics and All
Netflix AI Team Just Open-Sourced VOID: an AI Model That Erases Objects From Videos — Physics and All MarkTechPost
Netflix AI Team Just Open-Sourced VOID: an AI Model That Erases Objects From Videos — Physics and All matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: MarkTechPost published or updated this item on 2026-04-04.
Inside the Creative Artificial Intelligence (AI) Stack: Where Human Vision and Artificial Intelligence Meet to Design Future Fashion
Inside the Creative Artificial Intelligence (AI) Stack: Where Human Vision and Artificial Intelligence Meet to Design Future Fashion MarkTechPost
Inside the Creative Artificial Intelligence (AI) Stack: Where Human Vision and Artificial Intelligence Meet to Design Future Fashion matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: MarkTechPost published or updated this item on 2026-04-05.
Google DeepMind’s Research Lets an LLM Rewrite Its Own Game Theory Algorithms — And It Outperformed the Experts
Google DeepMind’s Research Lets an LLM Rewrite Its Own Game Theory Algorithms — And It Outperformed the Experts MarkTechPost
Google DeepMind’s Research Lets an LLM Rewrite Its Own Game Theory Algorithms — And It Outperformed the Experts matters because it signals momentum in llm and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: llm.
- Source context: MarkTechPost published or updated this item on 2026-04-03.
Inside Reflection AI: The $20B Open-Model Startup That Has Yet to Ship
Inside Reflection AI: The $20B Open-Model Startup That Has Yet to Ship turingpost.com
Inside Reflection AI: The $20B Open-Model Startup That Has Yet to Ship matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: Turing Post published or updated this item on 2026-03-08.
A “diff” tool for AI: Finding behavioral differences in new models
A “diff” tool for AI: Finding behavioral differences in new models Anthropic
A “diff” tool for AI: Finding behavioral differences in new models matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: Anthropic Research published or updated this item on 2026-03-13.
QuantumBlack: A Global Force in Agentic AI Transformation
QuantumBlack: A Global Force in Agentic AI Transformation AI Magazine
QuantumBlack: A Global Force in Agentic AI Transformation matters because it signals momentum in agent and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent.
- Source context: AI Magazine published or updated this item on 2026-03-16.
OpenAI Model Craft: Parameter Golf
OpenAI Model Craft: Parameter Golf OpenAI
OpenAI Model Craft: Parameter Golf matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: OpenAI Research published or updated this item on 2026-03-18.

Build a Domain-Specific Embedding Model in Under a Day
A Blog post by NVIDIA on Hugging Face
Build a Domain-Specific Embedding Model in Under a Day matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: Hugging Face Blog published or updated this item on 2026-03-20.
Protecting people from harmful manipulation
Google DeepMind researches AI's harmful manipulation risks across areas like finance and health, leading to new safety measures.
Protecting people from harmful manipulation matters because it signals momentum in safety and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: safety.
- Source context: DeepMind Blog published or updated this item on 2026-03-25.

Gemini 3.1 Flash Live: Making audio AI more natural and reliable
Our latest voice model has improved precision and lower latency to make voice interactions more fluid, natural and precise.
Gemini 3.1 Flash Live: Making audio AI more natural and reliable matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: DeepMind Blog published or updated this item on 2026-03-26.
Anthropic leak reveals new model "Claude Mythos" with "dramatically higher scores on tests" than any previous model
Anthropic leak reveals new model "Claude Mythos" with "dramatically higher scores on tests" than any previous model the-decoder.com
Anthropic leak reveals new model "Claude Mythos" with "dramatically higher scores on tests" than any previous model matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: The Decoder published or updated this item on 2026-03-28.
AI benchmarks are broken. Here’s what we need instead.
AI benchmarks are broken. Here’s what we need instead. MIT Technology Review
AI benchmarks are broken. Here’s what we need instead. matters because it signals momentum in benchmark and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: benchmark.
- Source context: MIT Tech Review AI published or updated this item on 2026-03-31.

Granite 4.0 3B Vision: Compact Multimodal Intelligence for Enterprise Documents
A Blog post by IBM Granite on Hugging Face
Granite 4.0 3B Vision: Compact Multimodal Intelligence for Enterprise Documents matters because it signals momentum in multimodal and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: multimodal.
- Source context: Hugging Face Blog published or updated this item on 2026-03-31.

TRL v1.0: Post-Training Library Built to Move with the Field
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
TRL v1.0: Post-Training Library Built to Move with the Field matters because it signals momentum in training and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: training.
- Source context: Hugging Face Blog published or updated this item on 2026-03-31.

KPMG: Inside the AI agent playbook driving enterprise margin gains
Global AI investment is accelerating, yet KPMG data shows the gap between enterprise AI spend and measurable business value is widening fast. The headline figure from KPMG’s first quarterly Global AI Pulse survey is blunt: despite global organisations planning to spend a...
KPMG: Inside the AI agent playbook driving enterprise margin gains matters because it signals momentum in agent and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent.
- Source context: AI News published or updated this item on 2026-04-01.
LWiAI Podcast #238 - GPT 5.4 mini, OpenAI Pivot, Mamba 3, Attention Residuals
OpenAI ships GPT-5.4 mini and nano, faster and more capable but up to 4x pricier, DLSS 5 looks like a real-time generative AI filter for video games | The Verge, and more!
LWiAI Podcast #238 - GPT 5.4 mini, OpenAI Pivot, Mamba 3, Attention Residuals matters because it signals momentum in gpt and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: gpt.
- Source context: Last Week in AI published or updated this item on 2026-04-01.
The gig workers who are training humanoid robots at home
The gig workers who are training humanoid robots at home MIT Technology Review
The gig workers who are training humanoid robots at home matters because it signals momentum in training and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: training.
- Source context: MIT Tech Review AI published or updated this item on 2026-04-01.
Emotion concepts and their function in a large language model
Emotion concepts and their function in a large language model Anthropic
Emotion concepts and their function in a large language model matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: Anthropic Research published or updated this item on 2026-04-02.
Anthropic cuts off third-party tools like OpenClaw for Claude subscribers, citing unsustainable demand
Anthropic cuts off third-party tools like OpenClaw for Claude subscribers, citing unsustainable demand the-decoder.com
Anthropic cuts off third-party tools like OpenClaw for Claude subscribers, citing unsustainable demand matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: The Decoder published or updated this item on 2026-04-04.

Last Week in AI #338 - Anthropic sues Trump, xAI starting over, Iran AI Fakes
Anthropic sues Trump administration in AI dispute with Pentagon, ‘Not built right the first time’ — Musk’s xAI is starting over again, again, Cascade of A.I. Fakes About War With Iran Causes Chaos Onl
Last Week in AI #338 - Anthropic sues Trump, xAI starting over, Iran AI Fakes matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Last Week in AI published or updated this item on 2026-03-16.

Measuring progress toward AGI: A cognitive framework
We’re introducing a framework to measure progress toward AGI, and launching a Kaggle hackathon to build the relevant evaluations.
Measuring progress toward AGI: A cognitive framework matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: DeepMind Blog published or updated this item on 2026-03-17.
How Apple's US$600bn US Investment Helps AI Infrastructure
How Apple's US$600bn US Investment Helps AI Infrastructure AI Magazine
How Apple's US$600bn US Investment Helps AI Infrastructure matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: AI Magazine published or updated this item on 2026-03-18.
Top 10: AI Platforms for Retail
Top 10: AI Platforms for Retail AI Magazine
Top 10: AI Platforms for Retail matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: AI Magazine published or updated this item on 2026-03-18.
The Org Age of AI
The Org Age of AI turingpost.com
The Org Age of AI matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Turing Post published or updated this item on 2026-03-22.
Last Week in AI #339 - DLSS 5, OpenAI Superapp, MiniMax M2.7
DLSS 5 looks like a real-time generative AI filter for video games, OpenAI Reportedly Pivoting to a Focus on Business and Productivity Only, and more!
Last Week in AI #339 - DLSS 5, OpenAI Superapp, MiniMax M2.7 matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Last Week in AI published or updated this item on 2026-03-23.
Vibe physics: The AI grad student
Vibe physics: The AI grad student Anthropic
Vibe physics: The AI grad student matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Anthropic Research published or updated this item on 2026-03-23.
Anthropic Economic Index report: Learning curves
Anthropic Economic Index report: Learning curves Anthropic
Anthropic Economic Index report: Learning curves matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Anthropic Research published or updated this item on 2026-03-24.

Lyria 3 Pro: Create longer tracks in more
Introducing Lyria 3 Pro, which unlocks longer tracks with structural awareness. We’re also bringing Lyria to more Google products and surfaces.
Lyria 3 Pro: Create longer tracks in more matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: DeepMind Blog published or updated this item on 2026-03-25.

Liberate your OpenClaw
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Liberate your OpenClaw matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Hugging Face Blog published or updated this item on 2026-03-27.
14 JEPA Milestones as a Map of AI Progress
14 JEPA Milestones as a Map of AI Progress turingpost.com
14 JEPA Milestones as a Map of AI Progress matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Turing Post published or updated this item on 2026-03-29.
The Pentagon’s culture war tactic against Anthropic has backfired
The Pentagon’s culture war tactic against Anthropic has backfired MIT Technology Review
The Pentagon’s culture war tactic against Anthropic has backfired matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: MIT Tech Review AI published or updated this item on 2026-03-30.
There are more AI health tools than ever—but how well do they work?
There are more AI health tools than ever—but how well do they work? MIT Technology Review
There are more AI health tools than ever—but how well do they work? matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: MIT Tech Review AI published or updated this item on 2026-03-30.
Anthropic accidentally publishes Claude Code source code for anyone to find
Anthropic accidentally publishes Claude Code source code for anyone to find the-decoder.com
Anthropic accidentally publishes Claude Code source code for anyone to find matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: The Decoder published or updated this item on 2026-03-31.
Gradient Labs gives every bank customer an AI account manager
Gradient Labs gives every bank customer an AI account manager OpenAI
Gradient Labs gives every bank customer an AI account manager matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: OpenAI Research published or updated this item on 2026-03-31.
How Australia Uses Claude: Findings from the Anthropic Economic Index
How Australia Uses Claude: Findings from the Anthropic Economic Index Anthropic
How Australia Uses Claude: Findings from the Anthropic Economic Index matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Anthropic Research published or updated this item on 2026-03-31.
OpenAI raises $122 billion to accelerate the next phase of AI
OpenAI raises $122 billion to accelerate the next phase of AI OpenAI
OpenAI raises $122 billion to accelerate the next phase of AI matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: OpenAI Research published or updated this item on 2026-03-31.
Codex now offers pay-as-you-go pricing for teams
Codex now offers pay-as-you-go pricing for teams OpenAI
Codex now offers pay-as-you-go pricing for teams matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: OpenAI Research published or updated this item on 2026-04-01.

Falcon Perception
A Blog post by Technology Innovation Institute on Hugging Face
Falcon Perception matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Hugging Face Blog published or updated this item on 2026-04-01.

Hershey applies AI across its supply chain operations
Artificial intelligence is moving beyond software and further into the physical side of business. Companies in food production and logistics are starting to use data systems to support day-to-day decisions, not long-term planning. That change is visible in The Hershey...
Hershey applies AI across its supply chain operations matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: AI News published or updated this item on 2026-04-01.

Experian uncovers fraud paradox in financial services’ AI adoption
The same technology that financial institutions deploying is being weaponised against them. That is the core tension running through Experian’s 2026 Future of Fraud Forecast, and it’s a tension the company is in a position to name because it sits on both sides of it....
Experian uncovers fraud paradox in financial services’ AI adoption matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: AI News published or updated this item on 2026-04-02.
Google's Gemma 4 is now available with Apache 2.0 licensing for the first time
Google's Gemma 4 is now available with Apache 2.0 licensing for the first time the-decoder.com
Google's Gemma 4 is now available with Apache 2.0 licensing for the first time matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: The Decoder published or updated this item on 2026-04-02.
OpenAI acquires TBPN
OpenAI acquires TBPN OpenAI
OpenAI acquires TBPN matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: OpenAI Research published or updated this item on 2026-04-02.
LWiAI Podcast #237 - Nemotron 3 Super, xAI reborn, Anthropic Lawsuit, Research!
Nemotron 3 Super: An Open Hybrid Mamba-Transformer MoE for Agentic Reasoning, Another XAI Cofounder Has Left, Anthropic Sues Department of Defense
LWiAI Podcast #237 - Nemotron 3 Super, xAI reborn, Anthropic Lawsuit, Research! matters because it affects the policy, supply-chain, or security constraints around AI development, especially across defense, agent, reasoning.
- Primary signals: defense, agent, reasoning.
- Source context: Last Week in AI published or updated this item on 2026-03-16.
5 best practices to secure AI systems
A decade ago, it would have been hard to believe that artificial intelligence could do what it can do now. However, it is this same power that introduces a new attack surface that traditional security frameworks were not built to address. As this technology becomes embedded...
5 best practices to secure AI systems matters because it affects the policy, supply-chain, or security constraints around AI development, especially across defense, security.
- Primary signals: defense, security.
- Source context: AI News published or updated this item on 2026-04-02.
Novee Introduces Autonomous AI Red Teaming to Uncover Security Flaws in LLM Applications
Novee Introduces Autonomous AI Red Teaming to Uncover Security Flaws in LLM Applications AI Magazine
Novee Introduces Autonomous AI Red Teaming to Uncover Security Flaws in LLM Applications matters because it affects the policy, supply-chain, or security constraints around AI development, especially across security, llm.
- Primary signals: security, llm.
- Source context: AI Magazine published or updated this item on 2026-03-25.
Holo3: Breaking the Computer Use Frontier
A Blog post by H company on Hugging Face
Holo3: Breaking the Computer Use Frontier matters because it affects the policy, supply-chain, or security constraints around AI development, especially across compute, frontier.
- Primary signals: compute, frontier.
- Source context: Hugging Face Blog published or updated this item on 2026-04-01.
DeepL’s Borderless Business report reveals 83% of enterprises are still behind on language AI
AI is everywhere in the enterprise. The translation workflow often is not. That is the core finding of DeepL’s 2026 Language AI report, “Borderless Business: Transforming Translation in the Age of AI,” published on March 10. Despite broad AI investment across business...
DeepL’s Borderless Business report reveals 83% of enterprises are still behind on language AI matters because it affects the policy, supply-chain, or security constraints around AI development, especially across border.
- Primary signals: border.
- Source context: AI News published or updated this item on 2026-04-01.
China’s Five-Year Plan details the targets for AI deployment
China has approved its 15th Five-Year Plan [PDF] setting out the country’s economic, education, social, and industrial priorities through to 2030. As might be expected, there is a significant number of references to AI, with the technology mentioned in several contexts. AI is...
China’s Five-Year Plan details the targets for AI deployment matters because it affects the policy, supply-chain, or security constraints around AI development, especially across china.
- Primary signals: china.
- Source context: AI News published or updated this item on 2026-04-02.
Agentic-MME: What Agentic Capability Really Brings to Multimodal Intelligence?
TL;DR: A new benchmark evaluates multimodal agentic capabilities by verifying tool usage and process efficiency rather than just final answers, revealing significant challenges in real-world multimodal problem-solving.
A new benchmark evaluates multimodal agentic capabilities by verifying tool usage and process efficiency rather than just final answers, revealing significant challenges in real-world multimodal problem-solving. Multimodal Large Language Models (MLLMs) are evolving from...
A new benchmark evaluates multimodal agentic capabilities by verifying tool usage and process efficiency rather than just final answers, revealing significant challenges in real-world multimodal problem-solving.
To address this, we introduce Agentic-MME , a process-verified benchmark for Multimodal Agentic Capabilities.
A new benchmark evaluates multimodal agentic capabilities by verifying tool usage and process efficiency rather than just final answers, revealing significant challenges in real-world multimodal problem-solving.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: A new benchmark evaluates multimodal agentic capabilities by verifying tool usage and process efficiency rather than just final answers, revealing significant challenges in real-world multimodal problem-solving.
- Method signal: To address this, we introduce Agentic-MME , a process-verified benchmark for Multimodal Agentic Capabilities.
- Evidence to watch: A new benchmark evaluates multimodal agentic capabilities by verifying tool usage and process efficiency rather than just final answers, revealing significant challenges in real-world multimodal problem-solving.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: A new benchmark evaluates multimodal agentic capabilities by verifying tool usage and process efficiency rather than just final answers, revealing significant challenges in real-world multimodal problem-solving.
- Approach: To address this, we introduce Agentic-MME , a process-verified benchmark for Multimodal Agentic Capabilities.
- Result signal: A new benchmark evaluates multimodal agentic capabilities by verifying tool usage and process efficiency rather than just final answers, revealing significant challenges in real-world multimodal...
- Community traction: Hugging Face Papers shows 15 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
Token Warping Helps MLLMs Look from Nearby Viewpoints
TL;DR: Token-level warping in vision-language models demonstrates superior stability and semantic coherence for viewpoint transformation compared to pixel-wise methods, achieving better visual reasoning performance.
Token-level warping in vision-language models demonstrates superior stability and semantic coherence for viewpoint transformation compared to pixel-wise methods, achieving better visual reasoning performance. Can warping tokens , rather than pixels, help multimodal large...
Token-level warping in vision-language models demonstrates superior stability and semantic coherence for viewpoint transformation compared to pixel-wise methods, achieving better visual reasoning performance.
Can warping tokens , rather than pixels, help multimodal large language models (MLLMs) understand how a scene appears from a nearby viewpoint?
Token-level warping in vision-language models demonstrates superior stability and semantic coherence for viewpoint transformation compared to pixel-wise methods, achieving better visual reasoning performance.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: Token-level warping in vision-language models demonstrates superior stability and semantic coherence for viewpoint transformation compared to pixel-wise methods, achieving better visual reasoning performance.
- Method signal: Can warping tokens , rather than pixels, help multimodal large language models (MLLMs) understand how a scene appears from a nearby viewpoint?
- Evidence to watch: Token-level warping in vision-language models demonstrates superior stability and semantic coherence for viewpoint transformation compared to pixel-wise methods, achieving better visual reasoning performance.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: Token-level warping in vision-language models demonstrates superior stability and semantic coherence for viewpoint transformation compared to pixel-wise methods, achieving better visual reasoning performance.
- Approach: Can warping tokens , rather than pixels, help multimodal large language models (MLLMs) understand how a scene appears from a nearby viewpoint?
- Result signal: Token-level warping in vision-language models demonstrates superior stability and semantic coherence for viewpoint transformation compared to pixel-wise methods, achieving better visual reasoning...
- Community traction: Hugging Face Papers shows 15 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
Xpertbench: Expert Level Tasks with Rubrics-Based Evaluation
TL;DR: XpertBench presents a comprehensive benchmark for evaluating large language models across professional domains using expert-curated tasks and a novel LLM-based evaluation approach called ShotJudge.
XpertBench presents a comprehensive benchmark for evaluating large language models across professional domains using expert-curated tasks and a novel LLM-based evaluation approach called ShotJudge. As Large Language Models (LLMs) exhibit plateauing performance on conventional...
XpertBench presents a comprehensive benchmark for evaluating large language models across professional domains using expert-curated tasks and a novel LLM-based evaluation approach called ShotJudge.
To bridge this gap, we present XpertBench , a high-fidelity benchmark engineered to assess LLMs across authentic professional domains .
As Large Language Models (LLMs) exhibit plateauing performance on conventional benchmarks, a pivotal challenge persists: evaluating their proficiency in complex, open-ended tasks characterizing genuine expert-level cognition .
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: XpertBench presents a comprehensive benchmark for evaluating large language models across professional domains using expert-curated tasks and a novel LLM-based evaluation approach called ShotJudge.
- Method signal: To bridge this gap, we present XpertBench , a high-fidelity benchmark engineered to assess LLMs across authentic professional domains .
- Evidence to watch: As Large Language Models (LLMs) exhibit plateauing performance on conventional benchmarks, a pivotal challenge persists: evaluating their proficiency in complex, open-ended tasks characterizing genuine expert-level cognition .
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: XpertBench presents a comprehensive benchmark for evaluating large language models across professional domains using expert-curated tasks and a novel LLM-based evaluation approach called ShotJudge.
- Approach: To bridge this gap, we present XpertBench , a high-fidelity benchmark engineered to assess LLMs across authentic professional domains .
- Result signal: As Large Language Models (LLMs) exhibit plateauing performance on conventional benchmarks, a pivotal challenge persists: evaluating their proficiency in complex, open-ended tasks characterizing genuine...
- Community traction: Hugging Face Papers shows 2 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
Self-Distilled RLVR
TL;DR: RLSD combines reinforcement learning with verifiable rewards and self-distillation to achieve stable training with fine-grained updates and reliable policy direction from environmental feedback.
RLSD combines reinforcement learning with verifiable rewards and self-distillation to achieve stable training with fine-grained updates and reliable policy direction from environmental feedback. On-policy distillation (OPD) has become a popular training paradigm in the LLM...
RLSD combines reinforcement learning with verifiable rewards and self-distillation to achieve stable training with fine-grained updates and reliable policy direction from environmental feedback.
This paper demonstrates that learning signals solely derived from the privileged teacher result in severe information leakage and unstable long-term training.
RLSD combines reinforcement learning with verifiable rewards and self-distillation to achieve stable training with fine-grained updates and reliable policy direction from environmental feedback.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: RLSD combines reinforcement learning with verifiable rewards and self-distillation to achieve stable training with fine-grained updates and reliable policy direction from environmental feedback.
- Method signal: This paper demonstrates that learning signals solely derived from the privileged teacher result in severe information leakage and unstable long-term training.
- Evidence to watch: RLSD combines reinforcement learning with verifiable rewards and self-distillation to achieve stable training with fine-grained updates and reliable policy direction from environmental feedback.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: RLSD combines reinforcement learning with verifiable rewards and self-distillation to achieve stable training with fine-grained updates and reliable policy direction from environmental feedback.
- Approach: This paper demonstrates that learning signals solely derived from the privileged teacher result in severe information leakage and unstable long-term training.
- Result signal: RLSD combines reinforcement learning with verifiable rewards and self-distillation to achieve stable training with fine-grained updates and reliable policy direction from environmental feedback.
- Community traction: Hugging Face Papers shows 10 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
A Simple Baseline for Streaming Video Understanding
TL;DR: A simple sliding-window approach using recent video frames outperforms complex memory-based streaming video understanding methods, revealing trade-offs between real-time perception and long-term memory capabilities.
A simple sliding-window approach using recent video frames outperforms complex memory-based streaming video understanding methods, revealing trade-offs between real-time perception and long-term memory capabilities. Recent streaming video understanding methods increasingly...
We challenge this trend with a simple finding: a sliding-window baseline that feeds only the most recent N frames to an off-the-shelf VLM already matches or surpasses published streaming models.
Recent streaming video understanding methods increasingly rely on complex memory mechanisms to handle long video streams.
A simple sliding-window approach using recent video frames outperforms complex memory-based streaming video understanding methods, revealing trade-offs between real-time perception and long-term memory capabilities.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: We challenge this trend with a simple finding: a sliding-window baseline that feeds only the most recent N frames to an off-the-shelf VLM already matches or surpasses published streaming models.
- Method signal: Recent streaming video understanding methods increasingly rely on complex memory mechanisms to handle long video streams.
- Evidence to watch: A simple sliding-window approach using recent video frames outperforms complex memory-based streaming video understanding methods, revealing trade-offs between real-time perception and long-term memory capabilities.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: We challenge this trend with a simple finding: a sliding-window baseline that feeds only the most recent N frames to an off-the-shelf VLM already matches or surpasses published streaming models.
- Approach: Recent streaming video understanding methods increasingly rely on complex memory mechanisms to handle long video streams.
- Result signal: A simple sliding-window approach using recent video frames outperforms complex memory-based streaming video understanding methods, revealing trade-offs between real-time perception and long-term memory...
- Community traction: Hugging Face Papers shows 26 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
Issue routing and exits.
The daily edition stays aligned with the rest of the site while keeping the full issue readable end to end.
Navigation
Public desks
Issue
- 04/06/2026
- 61 total analyzed
- Readable issue route