Daily Edition
The expanded edition keeps the full analyst notes, paper breakdowns, geopolitical framing, and the complete feed selected into this run.
Topic of the day.
A dedicated daily topic chosen from the strongest signals in the run, with TL;DR, why-now framing, and a fuller analyst read.
AI model reliability, safety, and trust
TL;DR: AI model reliability, safety, and trust is today's clearest AI theme: Meta AI Releases EUPE: A Compact Vision Encoder Family Under 100M Parameters That Rivals Specialist Models Across Image Understanding, Dense Prediction, and VLM Tasks...
Why now: The topic shows up across MarkTechPost and OpenAI Research, DeepMind Blog, which means the same operating pressure is appearing through multiple lenses instead of only one announcement.
AI model reliability, safety, and trust deserves the slower read today because the supporting items cluster around model, safety. Meta AI Releases EUPE: A Compact Vision Encoder Family Under 100M Parameters That Rivals Specialist Models Across Image Understanding, Dense Prediction, and VLM Tasks -... matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices. The combined signal suggests teams should treat this as a real operating change rather than...
- MarkTechPost: Meta AI Releases EUPE: A Compact Vision Encoder Family Under 100M Parameters That Rivals Specialist Models Across Image Understanding, Dense Prediction, and VLM Tasks -... points to Meta AI Releases...
- OpenAI Research: Introducing the OpenAI Safety Fellowship points to Introducing the OpenAI Safety Fellowship matters because it signals momentum in safety and may shift how teams prioritize models, tooling, or...
- DeepMind Blog: Protecting people from harmful manipulation points to Protecting people from harmful manipulation matters because it signals momentum in safety and may shift how teams prioritize models, tooling, or...
- Meta AI Releases EUPE: A Compact Vision Encoder Family Under 100M Parameters That Rivals Specialist Models Across Image Understanding, Dense Prediction, and VLM Tasks -... (MarkTechPost | 2026-04-07)
- Introducing the OpenAI Safety Fellowship (OpenAI Research | 2026-04-06)
- Protecting people from harmful manipulation (DeepMind Blog | 2026-03-25)
Policy, chips, capital, and power.
Industrial strategy, compute supply, export controls, and big-company positioning shaping the AI balance of power.
Novee Introduces Autonomous AI Red Teaming to Uncover Security Flaws in LLM Applications
Novee Introduces Autonomous AI Red Teaming to Uncover Security Flaws in LLM Applications AI Magazine
Novee Introduces Autonomous AI Red Teaming to Uncover Security Flaws in LLM Applications matters because it affects the policy, supply-chain, or security constraints around AI development, especially across security, llm.
- Primary signals: security, llm.
- Source context: AI Magazine published or updated this item on 2026-03-25.

Holo3: Breaking the Computer Use Frontier
A Blog post by H company on Hugging Face
Holo3: Breaking the Computer Use Frontier matters because it affects the policy, supply-chain, or security constraints around AI development, especially across compute, frontier.
- Primary signals: compute, frontier.
- Source context: Hugging Face Blog published or updated this item on 2026-04-01.
Industrial policy for the Intelligence Age
Industrial policy for the Intelligence Age OpenAI
Industrial policy for the Intelligence Age matters because it affects the policy, supply-chain, or security constraints around AI development, especially across policy.
- Primary signals: policy.
- Source context: OpenAI Research published or updated this item on 2026-04-06.
Product, model, and platform movement.
Software, model, deployment, and competitive stories with the strongest operator and market signal in this edition.
AI 101: Hermes Agent – OpenClaw’s Rival? Differences and Best Use Cases
AI 101: Hermes Agent – OpenClaw’s Rival? Differences and Best Use Cases Turing Post
AI 101: Hermes Agent – OpenClaw’s Rival? Differences and Best Use Cases matters because it signals momentum in agent and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent.
- Source context: Turing Post published or updated this item on 2026-04-08.

Gemma 4: Byte for byte, the most capable open models
Gemma 4: Our most intelligent open models to date, purpose-built for advanced reasoning and agentic workflows.
Gemma 4: Byte for byte, the most capable open models matters because it signals momentum in agent, model, reasoning and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, model, reasoning.
- Source context: DeepMind Blog published or updated this item on 2026-04-02.
RightNow AI Releases AutoKernel: An Open-Source Framework that Applies an Autonomous Agent Loop to GPU Kernel Optimization for Arbitrary PyTorch Models
RightNow AI Releases AutoKernel: An Open-Source Framework that Applies an Autonomous Agent Loop to GPU Kernel Optimization for Arbitrary PyTorch Models MarkTechPost
RightNow AI Releases AutoKernel: An Open-Source Framework that Applies an Autonomous Agent Loop to GPU Kernel Optimization for Arbitrary PyTorch Models matters because it signals momentum in agent, model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, model.
- Source context: MarkTechPost published or updated this item on 2026-04-06.
Enabling agent-first process redesign
Enabling agent-first process redesign MIT Technology Review
Enabling agent-first process redesign matters because it signals momentum in agent and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent.
- Source context: MIT Tech Review AI published or updated this item on 2026-04-07.
Meta AI Releases EUPE: A Compact Vision Encoder Family Under 100M Parameters That Rivals Specialist Models Across Image Understanding, Dense Prediction, and VLM Tasks -...
Meta AI Releases EUPE: A Compact Vision Encoder Family Under 100M Parameters That Rivals Specialist Models Across Image Understanding, Dense Prediction, and VLM Tasks MarkTechPost
Meta AI Releases EUPE: A Compact Vision Encoder Family Under 100M Parameters That Rivals Specialist Models Across Image Understanding, Dense Prediction, and VLM Tasks -... matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: MarkTechPost published or updated this item on 2026-04-07.
Differentiated source coverage.
Stories drawn from research blogs, first-party lab posts, practitioner newsletters, and selected technical outlets so the edition does not mirror the same headline across every source.

A New Framework for Evaluating Voice Agents (EVA)
A Blog post by ServiceNow-AI on Hugging Face
A New Framework for Evaluating Voice Agents (EVA) matters because it signals momentum in agent, agents and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, agents.
- Source context: Hugging Face Blog published or updated this item on 2026-03-24.
OpenAI raises $122 billion to accelerate the next phase of AI
OpenAI raises $122 billion to accelerate the next phase of AI OpenAI
OpenAI raises $122 billion to accelerate the next phase of AI matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: OpenAI Research published or updated this item on 2026-03-31.
A “diff” tool for AI: Finding behavioral differences in new models
A “diff” tool for AI: Finding behavioral differences in new models Anthropic
A “diff” tool for AI: Finding behavioral differences in new models matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: Anthropic Research published or updated this item on 2026-03-13.

Gemini 3.1 Flash Live: Making audio AI more natural and reliable
Our latest voice model has improved precision and lower latency to make voice interactions more fluid, natural and precise.
Gemini 3.1 Flash Live: Making audio AI more natural and reliable matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: DeepMind Blog published or updated this item on 2026-03-26.
Meet ‘AutoAgent’: The Open-Source Library That Lets an AI Engineer and Optimize Its Own Agent Harness Overnight
Meet ‘AutoAgent’: The Open-Source Library That Lets an AI Engineer and Optimize Its Own Agent Harness Overnight MarkTechPost
Meet ‘AutoAgent’: The Open-Source Library That Lets an AI Engineer and Optimize Its Own Agent Harness Overnight matters because it signals momentum in agent and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent.
- Source context: MarkTechPost published or updated this item on 2026-04-05.
Why Iran is Threatening OpenAI's Stargate Project
Why Iran is Threatening OpenAI's Stargate Project AI Magazine
Why Iran is Threatening OpenAI's Stargate Project matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: AI Magazine published or updated this item on 2026-04-07.
AI benchmarks are broken. Here’s what we need instead.
AI benchmarks are broken. Here’s what we need instead. MIT Technology Review
AI benchmarks are broken. Here’s what we need instead. matters because it signals momentum in benchmark and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: benchmark.
- Source context: MIT Tech Review AI published or updated this item on 2026-03-31.
The Org Age of AI
The Org Age of AI Turing Post
The Org Age of AI matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Turing Post published or updated this item on 2026-03-22.
Method, limitations, and results.
Paper summaries, methodology notes, limitations, and deep-dive bullets for the research items selected into the digest.
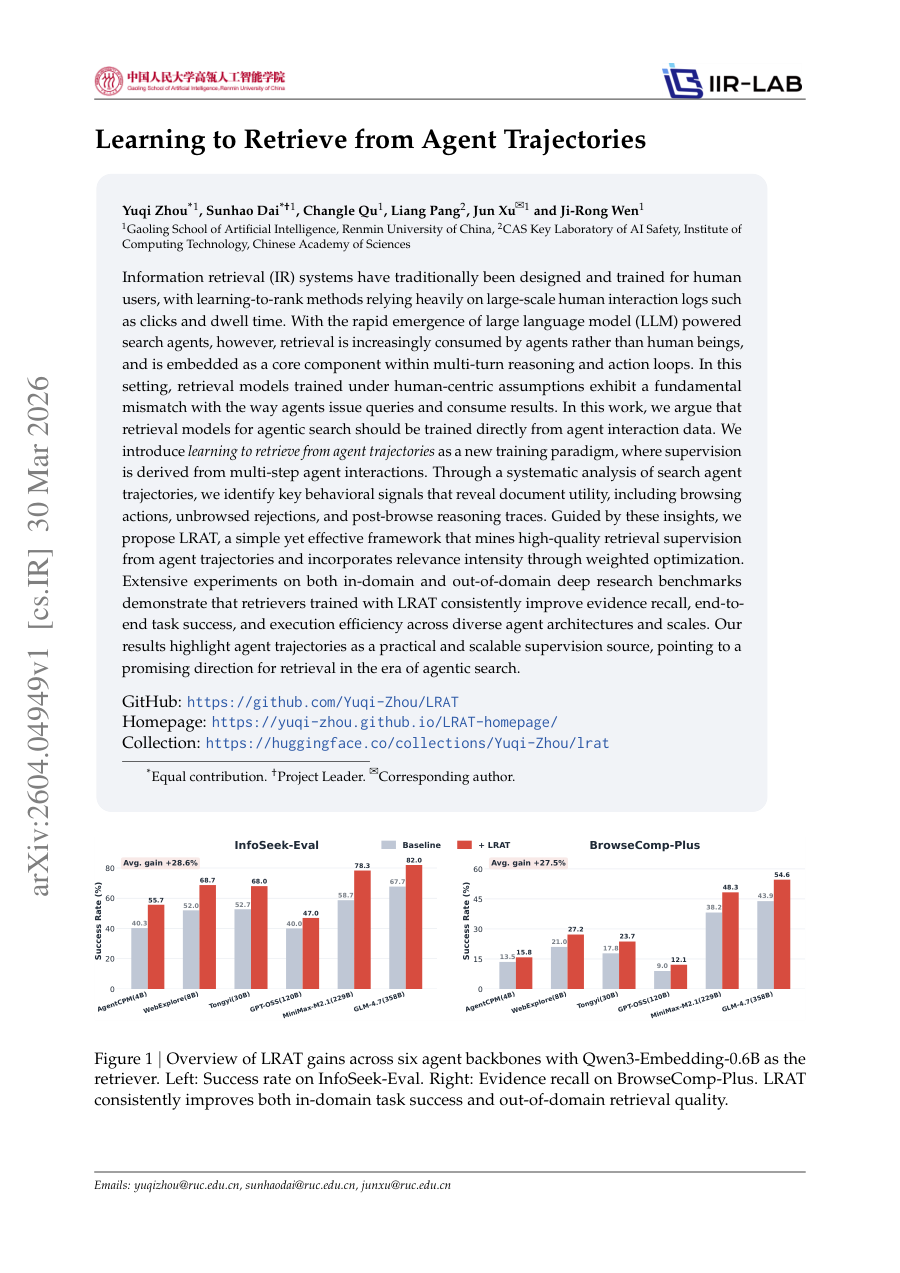
Learning to Retrieve from Agent Trajectories
TL;DR: Retrieval models for agentic search should be trained directly from agent interaction data using a new paradigm that mines supervision from multi-step agent trajectories and incorporates relevance intensity through...
Retrieval models for agentic search should be trained directly from agent interaction data using a new paradigm that mines supervision from multi-step agent trajectories and incorporates relevance intensity through weighted optimization. Information retrieval (IR) systems...
Extensive experiments on both in-domain and out-of-domain deep research benchmarks demonstrate that retrievers trained with LRAT consistently improve evidence recall , end-to-end task success , and execution efficiency across diverse agent architectures...
We introduce learning to retrieve from agent trajectories as a new training paradigm, where supervision is derived from multi-step agent interactions.
Through a systematic analysis of search agent trajectories , we identify key behavioral signals that reveal document utility, including browsing actions, unbrowsed rejections, and post-browse reasoning traces.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: Extensive experiments on both in-domain and out-of-domain deep research benchmarks demonstrate that retrievers trained with LRAT consistently improve evidence recall , end-to-end task success , and execution efficiency across diverse agent...
- Method signal: We introduce learning to retrieve from agent trajectories as a new training paradigm, where supervision is derived from multi-step agent interactions.
- Evidence to watch: Through a systematic analysis of search agent trajectories , we identify key behavioral signals that reveal document utility, including browsing actions, unbrowsed rejections, and post-browse reasoning traces.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: Extensive experiments on both in-domain and out-of-domain deep research benchmarks demonstrate that retrievers trained with LRAT consistently improve evidence recall , end-to-end task success , and execution...
- Approach: We introduce learning to retrieve from agent trajectories as a new training paradigm, where supervision is derived from multi-step agent interactions.
- Result signal: Through a systematic analysis of search agent trajectories , we identify key behavioral signals that reveal document utility, including browsing actions, unbrowsed rejections, and post-browse reasoning...
- Community traction: Hugging Face Papers shows 30 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.

Claw-Eval: Toward Trustworthy Evaluation of Autonomous Agents
TL;DR: Claw-Eval addresses limitations in agent benchmarks by providing comprehensive evaluation across multiple modalities with trajectory-aware grading and safety assessments.
Claw-Eval addresses limitations in agent benchmarks by providing comprehensive evaluation across multiple modalities with trajectory-aware grading and safety assessments. Large language models are increasingly deployed as autonomous agents executing multi-step workflows in...
It comprises 300 human-verified tasks spanning 9 categories across three groups (general service orchestration, multimodal perception and generation, and multi-turn professional dialogue).
We introduce Claw-Eval, an end-to-end evaluation suite addressing all three gaps.
Claw-Eval addresses limitations in agent benchmarks by providing comprehensive evaluation across multiple modalities with trajectory-aware grading and safety assessments.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: It comprises 300 human-verified tasks spanning 9 categories across three groups (general service orchestration, multimodal perception and generation, and multi-turn professional dialogue).
- Method signal: We introduce Claw-Eval, an end-to-end evaluation suite addressing all three gaps.
- Evidence to watch: Claw-Eval addresses limitations in agent benchmarks by providing comprehensive evaluation across multiple modalities with trajectory-aware grading and safety assessments.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: It comprises 300 human-verified tasks spanning 9 categories across three groups (general service orchestration, multimodal perception and generation, and multi-turn professional dialogue).
- Approach: We introduce Claw-Eval, an end-to-end evaluation suite addressing all three gaps.
- Result signal: Claw-Eval addresses limitations in agent benchmarks by providing comprehensive evaluation across multiple modalities with trajectory-aware grading and safety assessments.
- Community traction: Hugging Face Papers shows 52 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.

ThinkTwice: Jointly Optimizing Large Language Models for Reasoning and Self-Refinement
TL;DR: ThinkTwice is a two-phase framework that jointly optimizes large language models for reasoning and self-refinement using Group Relative Policy Optimization, demonstrating improved performance on mathematical...
ThinkTwice is a two-phase framework that jointly optimizes large language models for reasoning and self-refinement using Group Relative Policy Optimization, demonstrating improved performance on mathematical reasoning benchmarks. We introduce ThinkTwice, a simple two-phase...
We introduce ThinkTwice, a simple two-phase framework that jointly optimizes LLMs to solve reasoning problems and refine the answers, based on Group Relative Policy Optimization (GRPO).
We introduce ThinkTwice, a simple two-phase framework that jointly optimizes LLMs to solve reasoning problems and refine the answers, based on Group Relative Policy Optimization (GRPO).
ThinkTwice is a two-phase framework that jointly optimizes large language models for reasoning and self-refinement using Group Relative Policy Optimization, demonstrating improved performance on mathematical reasoning benchmarks.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: We introduce ThinkTwice, a simple two-phase framework that jointly optimizes LLMs to solve reasoning problems and refine the answers, based on Group Relative Policy Optimization (GRPO).
- Method signal: We introduce ThinkTwice, a simple two-phase framework that jointly optimizes LLMs to solve reasoning problems and refine the answers, based on Group Relative Policy Optimization (GRPO).
- Evidence to watch: ThinkTwice is a two-phase framework that jointly optimizes large language models for reasoning and self-refinement using Group Relative Policy Optimization, demonstrating improved performance on mathematical reasoning benchmarks.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: We introduce ThinkTwice, a simple two-phase framework that jointly optimizes LLMs to solve reasoning problems and refine the answers, based on Group Relative Policy Optimization (GRPO).
- Approach: We introduce ThinkTwice, a simple two-phase framework that jointly optimizes LLMs to solve reasoning problems and refine the answers, based on Group Relative Policy Optimization (GRPO).
- Result signal: ThinkTwice is a two-phase framework that jointly optimizes large language models for reasoning and self-refinement using Group Relative Policy Optimization, demonstrating improved performance on...
- Community traction: Hugging Face Papers shows 22 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.

Video-MME-v2: Towards the Next Stage in Benchmarks for Comprehensive Video Understanding
TL;DR: Video-MME-v2 presents a comprehensive benchmark for evaluating video understanding models through a progressive hierarchy and group-based evaluation to assess robustness and faithfulness.
Video-MME-v2 presents a comprehensive benchmark for evaluating video understanding models through a progressive hierarchy and group-based evaluation to assess robustness and faithfulness. With the rapid advancement of video understanding , existing benchmarks are becoming...
Extensive experiments reveal a substantial gap between current best model Gemini-3-Pro and human experts, and uncover a clear hierarchical bottleneck where errors in visual information aggregation and temporal modeling propagate to limit high-level reasoning .
To address this widening gap, we introduce Video-MME-v2, a comprehensive benchmark designed to rigorously evaluate the robustness and faithfulness of video understanding .
With the rapid advancement of video understanding , existing benchmarks are becoming increasingly saturated, exposing a critical discrepancy between inflated leaderboard scores and real-world model capabilities.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: Extensive experiments reveal a substantial gap between current best model Gemini-3-Pro and human experts, and uncover a clear hierarchical bottleneck where errors in visual information aggregation and temporal modeling propagate to limit...
- Method signal: To address this widening gap, we introduce Video-MME-v2, a comprehensive benchmark designed to rigorously evaluate the robustness and faithfulness of video understanding .
- Evidence to watch: With the rapid advancement of video understanding , existing benchmarks are becoming increasingly saturated, exposing a critical discrepancy between inflated leaderboard scores and real-world model capabilities.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: Extensive experiments reveal a substantial gap between current best model Gemini-3-Pro and human experts, and uncover a clear hierarchical bottleneck where errors in visual information aggregation and...
- Approach: To address this widening gap, we introduce Video-MME-v2, a comprehensive benchmark designed to rigorously evaluate the robustness and faithfulness of video understanding .
- Result signal: With the rapid advancement of video understanding , existing benchmarks are becoming increasingly saturated, exposing a critical discrepancy between inflated leaderboard scores and real-world model...
- Community traction: Hugging Face Papers shows 93 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.

Beyond Accuracy: Unveiling Inefficiency Patterns in Tool-Integrated Reasoning
TL;DR: Researchers introduce PTE (Prefill Token Equivalents), a hardware-aware metric for measuring efficiency in Tool-Integrated Reasoning scenarios, which better correlates with actual inference latency than traditional...
Researchers introduce PTE (Prefill Token Equivalents), a hardware-aware metric for measuring efficiency in Tool-Integrated Reasoning scenarios, which better correlates with actual inference latency than traditional token counts by accounting for KV-Cache inefficiencies and...
Researchers introduce PTE (Prefill Token Equivalents), a hardware-aware metric for measuring efficiency in Tool-Integrated Reasoning scenarios, which better correlates with actual inference latency than traditional token counts by accounting for KV-Cache...
Researchers introduce PTE (Prefill Token Equivalents), a hardware-aware metric for measuring efficiency in Tool-Integrated Reasoning scenarios, which better correlates with actual inference latency than traditional token counts by accounting for KV-Cache inefficiencies and long tool responses.
Researchers introduce PTE (Prefill Token Equivalents), a hardware-aware metric for measuring efficiency in Tool-Integrated Reasoning scenarios, which better correlates with actual inference latency than traditional token counts by accounting for KV-Cache inefficiencies and long tool responses.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: Researchers introduce PTE (Prefill Token Equivalents), a hardware-aware metric for measuring efficiency in Tool-Integrated Reasoning scenarios, which better correlates with actual inference latency than traditional token counts by...
- Method signal: Researchers introduce PTE (Prefill Token Equivalents), a hardware-aware metric for measuring efficiency in Tool-Integrated Reasoning scenarios, which better correlates with actual inference latency than traditional token counts by accounting...
- Evidence to watch: Researchers introduce PTE (Prefill Token Equivalents), a hardware-aware metric for measuring efficiency in Tool-Integrated Reasoning scenarios, which better correlates with actual inference latency than traditional token counts by...
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: Researchers introduce PTE (Prefill Token Equivalents), a hardware-aware metric for measuring efficiency in Tool-Integrated Reasoning scenarios, which better correlates with actual inference latency than...
- Approach: Researchers introduce PTE (Prefill Token Equivalents), a hardware-aware metric for measuring efficiency in Tool-Integrated Reasoning scenarios, which better correlates with actual inference latency than...
- Result signal: Researchers introduce PTE (Prefill Token Equivalents), a hardware-aware metric for measuring efficiency in Tool-Integrated Reasoning scenarios, which better correlates with actual inference latency...
- Community traction: Hugging Face Papers shows 22 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
Everything selected into the run.
The complete analyzed stream for the issue, useful when you want to scan the entire run instead of only the curated front page.
AI 101: Hermes Agent – OpenClaw’s Rival? Differences and Best Use Cases
AI 101: Hermes Agent – OpenClaw’s Rival? Differences and Best Use Cases Turing Post
AI 101: Hermes Agent – OpenClaw’s Rival? Differences and Best Use Cases matters because it signals momentum in agent and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent.
- Source context: Turing Post published or updated this item on 2026-04-08.
Gemma 4: Byte for byte, the most capable open models
Gemma 4: Our most intelligent open models to date, purpose-built for advanced reasoning and agentic workflows.
Gemma 4: Byte for byte, the most capable open models matters because it signals momentum in agent, model, reasoning and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, model, reasoning.
- Source context: DeepMind Blog published or updated this item on 2026-04-02.
RightNow AI Releases AutoKernel: An Open-Source Framework that Applies an Autonomous Agent Loop to GPU Kernel Optimization for Arbitrary PyTorch Models
RightNow AI Releases AutoKernel: An Open-Source Framework that Applies an Autonomous Agent Loop to GPU Kernel Optimization for Arbitrary PyTorch Models MarkTechPost
RightNow AI Releases AutoKernel: An Open-Source Framework that Applies an Autonomous Agent Loop to GPU Kernel Optimization for Arbitrary PyTorch Models matters because it signals momentum in agent, model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, model.
- Source context: MarkTechPost published or updated this item on 2026-04-06.
Enabling agent-first process redesign
Enabling agent-first process redesign MIT Technology Review
Enabling agent-first process redesign matters because it signals momentum in agent and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent.
- Source context: MIT Tech Review AI published or updated this item on 2026-04-07.
Meta AI Releases EUPE: A Compact Vision Encoder Family Under 100M Parameters That Rivals Specialist Models Across Image Understanding, Dense Prediction, and VLM Tasks -...
Meta AI Releases EUPE: A Compact Vision Encoder Family Under 100M Parameters That Rivals Specialist Models Across Image Understanding, Dense Prediction, and VLM Tasks MarkTechPost
Meta AI Releases EUPE: A Compact Vision Encoder Family Under 100M Parameters That Rivals Specialist Models Across Image Understanding, Dense Prediction, and VLM Tasks -... matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: MarkTechPost published or updated this item on 2026-04-07.
A New Framework for Evaluating Voice Agents (EVA)
A Blog post by ServiceNow-AI on Hugging Face
A New Framework for Evaluating Voice Agents (EVA) matters because it signals momentum in agent, agents and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, agents.
- Source context: Hugging Face Blog published or updated this item on 2026-03-24.
Introducing the OpenAI Safety Fellowship
Introducing the OpenAI Safety Fellowship OpenAI
Introducing the OpenAI Safety Fellowship matters because it signals momentum in safety and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: safety.
- Source context: OpenAI Research published or updated this item on 2026-04-06.
Meta employees compete for token consumption on an internal AI leaderboard
Meta employees compete for token consumption on an internal AI leaderboard the-decoder.com
Meta employees compete for token consumption on an internal AI leaderboard matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: The Decoder published or updated this item on 2026-04-07.
Why Iran is Threatening OpenAI's Stargate Project
Why Iran is Threatening OpenAI's Stargate Project AI Magazine
Why Iran is Threatening OpenAI's Stargate Project matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: AI Magazine published or updated this item on 2026-04-07.
Meet ‘AutoAgent’: The Open-Source Library That Lets an AI Engineer and Optimize Its Own Agent Harness Overnight
Meet ‘AutoAgent’: The Open-Source Library That Lets an AI Engineer and Optimize Its Own Agent Harness Overnight MarkTechPost
Meet ‘AutoAgent’: The Open-Source Library That Lets an AI Engineer and Optimize Its Own Agent Harness Overnight matters because it signals momentum in agent and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent.
- Source context: MarkTechPost published or updated this item on 2026-04-05.
A “diff” tool for AI: Finding behavioral differences in new models
A “diff” tool for AI: Finding behavioral differences in new models Anthropic
A “diff” tool for AI: Finding behavioral differences in new models matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: Anthropic Research published or updated this item on 2026-03-13.

Protecting people from harmful manipulation
Google DeepMind researches AI's harmful manipulation risks across areas like finance and health, leading to new safety measures.
Protecting people from harmful manipulation matters because it signals momentum in safety and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: safety.
- Source context: DeepMind Blog published or updated this item on 2026-03-25.
Gemini 3.1 Flash Live: Making audio AI more natural and reliable
Our latest voice model has improved precision and lower latency to make voice interactions more fluid, natural and precise.
Gemini 3.1 Flash Live: Making audio AI more natural and reliable matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: DeepMind Blog published or updated this item on 2026-03-26.
Anthropic leak reveals new model "Claude Mythos" with "dramatically higher scores on tests" than any previous model
Anthropic leak reveals new model "Claude Mythos" with "dramatically higher scores on tests" than any previous model the-decoder.com
Anthropic leak reveals new model "Claude Mythos" with "dramatically higher scores on tests" than any previous model matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: The Decoder published or updated this item on 2026-03-28.
AI benchmarks are broken. Here’s what we need instead.
AI benchmarks are broken. Here’s what we need instead. MIT Technology Review
AI benchmarks are broken. Here’s what we need instead. matters because it signals momentum in benchmark and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: benchmark.
- Source context: MIT Tech Review AI published or updated this item on 2026-03-31.

Granite 4.0 3B Vision: Compact Multimodal Intelligence for Enterprise Documents
A Blog post by IBM Granite on Hugging Face
Granite 4.0 3B Vision: Compact Multimodal Intelligence for Enterprise Documents matters because it signals momentum in multimodal and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: multimodal.
- Source context: Hugging Face Blog published or updated this item on 2026-03-31.

TRL v1.0: Post-Training Library Built to Move with the Field
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
TRL v1.0: Post-Training Library Built to Move with the Field matters because it signals momentum in training and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: training.
- Source context: Hugging Face Blog published or updated this item on 2026-03-31.
LWiAI Podcast #238 - GPT 5.4 mini, OpenAI Pivot, Mamba 3, Attention Residuals
OpenAI ships GPT-5.4 mini and nano, faster and more capable but up to 4x pricier, DLSS 5 looks like a real-time generative AI filter for video games | The Verge, and more!
LWiAI Podcast #238 - GPT 5.4 mini, OpenAI Pivot, Mamba 3, Attention Residuals matters because it signals momentum in gpt and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: gpt.
- Source context: Last Week in AI published or updated this item on 2026-04-01.
The gig workers who are training humanoid robots at home
The gig workers who are training humanoid robots at home MIT Technology Review
The gig workers who are training humanoid robots at home matters because it signals momentum in training and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: training.
- Source context: MIT Tech Review AI published or updated this item on 2026-04-01.
Emotion concepts and their function in a large language model
Emotion concepts and their function in a large language model Anthropic
Emotion concepts and their function in a large language model matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: Anthropic Research published or updated this item on 2026-04-02.
How to Build Production-Ready Agentic Systems with Z.AI GLM-5 Using Thinking Mode, Tool Calling, Streaming, and Multi-Turn Workflows
How to Build Production-Ready Agentic Systems with Z.AI GLM-5 Using Thinking Mode, Tool Calling, Streaming, and Multi-Turn Workflows MarkTechPost
How to Build Production-Ready Agentic Systems with Z.AI GLM-5 Using Thinking Mode, Tool Calling, Streaming, and Multi-Turn Workflows matters because it signals momentum in agent and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent.
- Source context: MarkTechPost published or updated this item on 2026-04-04.
Netflix AI Team Just Open-Sourced VOID: an AI Model That Erases Objects From Videos — Physics and All
Netflix AI Team Just Open-Sourced VOID: an AI Model That Erases Objects From Videos — Physics and All MarkTechPost
Netflix AI Team Just Open-Sourced VOID: an AI Model That Erases Objects From Videos — Physics and All matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: MarkTechPost published or updated this item on 2026-04-04.
AI is changing how small online sellers decide what to make
AI is changing how small online sellers decide what to make MIT Technology Review
AI is changing how small online sellers decide what to make matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: MIT Tech Review AI published or updated this item on 2026-04-06.
Exploring Infosys' Essential Steps to AI Readiness
Exploring Infosys' Essential Steps to AI Readiness AI Magazine
Exploring Infosys' Essential Steps to AI Readiness matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: AI Magazine published or updated this item on 2026-04-06.
Telehealth startup Medvi generated billions in revenue with AI-powered fake advertising
Telehealth startup Medvi generated billions in revenue with AI-powered fake advertising the-decoder.com
Telehealth startup Medvi generated billions in revenue with AI-powered fake advertising matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: The Decoder published or updated this item on 2026-04-06.
The one piece of data that could actually shed light on your job and AI
The one piece of data that could actually shed light on your job and AI MIT Technology Review
The one piece of data that could actually shed light on your job and AI matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: MIT Tech Review AI published or updated this item on 2026-04-06.
How Apple's US$600bn US Investment Helps AI Infrastructure
How Apple's US$600bn US Investment Helps AI Infrastructure AI Magazine
How Apple's US$600bn US Investment Helps AI Infrastructure matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: AI Magazine published or updated this item on 2026-03-18.
Top 10: AI Platforms for Retail
Top 10: AI Platforms for Retail AI Magazine
Top 10: AI Platforms for Retail matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: AI Magazine published or updated this item on 2026-03-18.
The Org Age of AI
The Org Age of AI Turing Post
The Org Age of AI matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Turing Post published or updated this item on 2026-03-22.
Last Week in AI #339 - DLSS 5, OpenAI Superapp, MiniMax M2.7
DLSS 5 looks like a real-time generative AI filter for video games, OpenAI Reportedly Pivoting to a Focus on Business and Productivity Only, and more!
Last Week in AI #339 - DLSS 5, OpenAI Superapp, MiniMax M2.7 matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Last Week in AI published or updated this item on 2026-03-23.
Long-running Claude for scientific computing
Long-running Claude for scientific computing Anthropic
Long-running Claude for scientific computing matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Anthropic Research published or updated this item on 2026-03-23.
Anthropic Economic Index report: Learning curves
Anthropic Economic Index report: Learning curves Anthropic
Anthropic Economic Index report: Learning curves matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Anthropic Research published or updated this item on 2026-03-24.

Lyria 3 Pro: Create longer tracks in more
Introducing Lyria 3 Pro, which unlocks longer tracks with structural awareness. We’re also bringing Lyria to more Google products and surfaces.
Lyria 3 Pro: Create longer tracks in more matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: DeepMind Blog published or updated this item on 2026-03-25.

Liberate your OpenClaw
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Liberate your OpenClaw matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Hugging Face Blog published or updated this item on 2026-03-27.
14 JEPA Milestones as a Map of AI Progress
14 JEPA Milestones as a Map of AI Progress Turing Post
14 JEPA Milestones as a Map of AI Progress matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Turing Post published or updated this item on 2026-03-29.
How Australia Uses Claude: Findings from the Anthropic Economic Index
How Australia Uses Claude: Findings from the Anthropic Economic Index Anthropic
How Australia Uses Claude: Findings from the Anthropic Economic Index matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Anthropic Research published or updated this item on 2026-03-31.
OpenAI raises $122 billion to accelerate the next phase of AI
OpenAI raises $122 billion to accelerate the next phase of AI OpenAI
OpenAI raises $122 billion to accelerate the next phase of AI matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: OpenAI Research published or updated this item on 2026-03-31.

Any Custom Frontend with Gradio's Backend
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Any Custom Frontend with Gradio's Backend matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Hugging Face Blog published or updated this item on 2026-04-01.
Codex now offers pay-as-you-go pricing for teams
Codex now offers pay-as-you-go pricing for teams OpenAI
Codex now offers pay-as-you-go pricing for teams matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: OpenAI Research published or updated this item on 2026-04-01.

Falcon Perception
A Blog post by Technology Innovation Institute on Hugging Face
Falcon Perception matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Hugging Face Blog published or updated this item on 2026-04-01.
OpenAI acquires TBPN
OpenAI acquires TBPN OpenAI
OpenAI acquires TBPN matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: OpenAI Research published or updated this item on 2026-04-02.
Anthropic cuts off third-party tools like OpenClaw for Claude subscribers, citing unsustainable demand
Anthropic cuts off third-party tools like OpenClaw for Claude subscribers, citing unsustainable demand the-decoder.com
Anthropic cuts off third-party tools like OpenClaw for Claude subscribers, citing unsustainable demand matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: The Decoder published or updated this item on 2026-04-04.
Novee Introduces Autonomous AI Red Teaming to Uncover Security Flaws in LLM Applications
Novee Introduces Autonomous AI Red Teaming to Uncover Security Flaws in LLM Applications AI Magazine
Novee Introduces Autonomous AI Red Teaming to Uncover Security Flaws in LLM Applications matters because it affects the policy, supply-chain, or security constraints around AI development, especially across security, llm.
- Primary signals: security, llm.
- Source context: AI Magazine published or updated this item on 2026-03-25.
Holo3: Breaking the Computer Use Frontier
A Blog post by H company on Hugging Face
Holo3: Breaking the Computer Use Frontier matters because it affects the policy, supply-chain, or security constraints around AI development, especially across compute, frontier.
- Primary signals: compute, frontier.
- Source context: Hugging Face Blog published or updated this item on 2026-04-01.
Industrial policy for the Intelligence Age
Industrial policy for the Intelligence Age OpenAI
Industrial policy for the Intelligence Age matters because it affects the policy, supply-chain, or security constraints around AI development, especially across policy.
- Primary signals: policy.
- Source context: OpenAI Research published or updated this item on 2026-04-06.
Learning to Retrieve from Agent Trajectories
TL;DR: Retrieval models for agentic search should be trained directly from agent interaction data using a new paradigm that mines supervision from multi-step agent trajectories and incorporates relevance intensity through...
Retrieval models for agentic search should be trained directly from agent interaction data using a new paradigm that mines supervision from multi-step agent trajectories and incorporates relevance intensity through weighted optimization. Information retrieval (IR) systems...
Extensive experiments on both in-domain and out-of-domain deep research benchmarks demonstrate that retrievers trained with LRAT consistently improve evidence recall , end-to-end task success , and execution efficiency across diverse agent architectures...
We introduce learning to retrieve from agent trajectories as a new training paradigm, where supervision is derived from multi-step agent interactions.
Through a systematic analysis of search agent trajectories , we identify key behavioral signals that reveal document utility, including browsing actions, unbrowsed rejections, and post-browse reasoning traces.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: Extensive experiments on both in-domain and out-of-domain deep research benchmarks demonstrate that retrievers trained with LRAT consistently improve evidence recall , end-to-end task success , and execution efficiency across diverse agent...
- Method signal: We introduce learning to retrieve from agent trajectories as a new training paradigm, where supervision is derived from multi-step agent interactions.
- Evidence to watch: Through a systematic analysis of search agent trajectories , we identify key behavioral signals that reveal document utility, including browsing actions, unbrowsed rejections, and post-browse reasoning traces.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: Extensive experiments on both in-domain and out-of-domain deep research benchmarks demonstrate that retrievers trained with LRAT consistently improve evidence recall , end-to-end task success , and execution...
- Approach: We introduce learning to retrieve from agent trajectories as a new training paradigm, where supervision is derived from multi-step agent interactions.
- Result signal: Through a systematic analysis of search agent trajectories , we identify key behavioral signals that reveal document utility, including browsing actions, unbrowsed rejections, and post-browse reasoning...
- Community traction: Hugging Face Papers shows 30 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
Claw-Eval: Toward Trustworthy Evaluation of Autonomous Agents
TL;DR: Claw-Eval addresses limitations in agent benchmarks by providing comprehensive evaluation across multiple modalities with trajectory-aware grading and safety assessments.
Claw-Eval addresses limitations in agent benchmarks by providing comprehensive evaluation across multiple modalities with trajectory-aware grading and safety assessments. Large language models are increasingly deployed as autonomous agents executing multi-step workflows in...
It comprises 300 human-verified tasks spanning 9 categories across three groups (general service orchestration, multimodal perception and generation, and multi-turn professional dialogue).
We introduce Claw-Eval, an end-to-end evaluation suite addressing all three gaps.
Claw-Eval addresses limitations in agent benchmarks by providing comprehensive evaluation across multiple modalities with trajectory-aware grading and safety assessments.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: It comprises 300 human-verified tasks spanning 9 categories across three groups (general service orchestration, multimodal perception and generation, and multi-turn professional dialogue).
- Method signal: We introduce Claw-Eval, an end-to-end evaluation suite addressing all three gaps.
- Evidence to watch: Claw-Eval addresses limitations in agent benchmarks by providing comprehensive evaluation across multiple modalities with trajectory-aware grading and safety assessments.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: It comprises 300 human-verified tasks spanning 9 categories across three groups (general service orchestration, multimodal perception and generation, and multi-turn professional dialogue).
- Approach: We introduce Claw-Eval, an end-to-end evaluation suite addressing all three gaps.
- Result signal: Claw-Eval addresses limitations in agent benchmarks by providing comprehensive evaluation across multiple modalities with trajectory-aware grading and safety assessments.
- Community traction: Hugging Face Papers shows 52 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
ThinkTwice: Jointly Optimizing Large Language Models for Reasoning and Self-Refinement
TL;DR: ThinkTwice is a two-phase framework that jointly optimizes large language models for reasoning and self-refinement using Group Relative Policy Optimization, demonstrating improved performance on mathematical...
ThinkTwice is a two-phase framework that jointly optimizes large language models for reasoning and self-refinement using Group Relative Policy Optimization, demonstrating improved performance on mathematical reasoning benchmarks. We introduce ThinkTwice, a simple two-phase...
We introduce ThinkTwice, a simple two-phase framework that jointly optimizes LLMs to solve reasoning problems and refine the answers, based on Group Relative Policy Optimization (GRPO).
We introduce ThinkTwice, a simple two-phase framework that jointly optimizes LLMs to solve reasoning problems and refine the answers, based on Group Relative Policy Optimization (GRPO).
ThinkTwice is a two-phase framework that jointly optimizes large language models for reasoning and self-refinement using Group Relative Policy Optimization, demonstrating improved performance on mathematical reasoning benchmarks.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: We introduce ThinkTwice, a simple two-phase framework that jointly optimizes LLMs to solve reasoning problems and refine the answers, based on Group Relative Policy Optimization (GRPO).
- Method signal: We introduce ThinkTwice, a simple two-phase framework that jointly optimizes LLMs to solve reasoning problems and refine the answers, based on Group Relative Policy Optimization (GRPO).
- Evidence to watch: ThinkTwice is a two-phase framework that jointly optimizes large language models for reasoning and self-refinement using Group Relative Policy Optimization, demonstrating improved performance on mathematical reasoning benchmarks.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: We introduce ThinkTwice, a simple two-phase framework that jointly optimizes LLMs to solve reasoning problems and refine the answers, based on Group Relative Policy Optimization (GRPO).
- Approach: We introduce ThinkTwice, a simple two-phase framework that jointly optimizes LLMs to solve reasoning problems and refine the answers, based on Group Relative Policy Optimization (GRPO).
- Result signal: ThinkTwice is a two-phase framework that jointly optimizes large language models for reasoning and self-refinement using Group Relative Policy Optimization, demonstrating improved performance on...
- Community traction: Hugging Face Papers shows 22 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
Video-MME-v2: Towards the Next Stage in Benchmarks for Comprehensive Video Understanding
TL;DR: Video-MME-v2 presents a comprehensive benchmark for evaluating video understanding models through a progressive hierarchy and group-based evaluation to assess robustness and faithfulness.
Video-MME-v2 presents a comprehensive benchmark for evaluating video understanding models through a progressive hierarchy and group-based evaluation to assess robustness and faithfulness. With the rapid advancement of video understanding , existing benchmarks are becoming...
Extensive experiments reveal a substantial gap between current best model Gemini-3-Pro and human experts, and uncover a clear hierarchical bottleneck where errors in visual information aggregation and temporal modeling propagate to limit high-level reasoning .
To address this widening gap, we introduce Video-MME-v2, a comprehensive benchmark designed to rigorously evaluate the robustness and faithfulness of video understanding .
With the rapid advancement of video understanding , existing benchmarks are becoming increasingly saturated, exposing a critical discrepancy between inflated leaderboard scores and real-world model capabilities.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: Extensive experiments reveal a substantial gap between current best model Gemini-3-Pro and human experts, and uncover a clear hierarchical bottleneck where errors in visual information aggregation and temporal modeling propagate to limit...
- Method signal: To address this widening gap, we introduce Video-MME-v2, a comprehensive benchmark designed to rigorously evaluate the robustness and faithfulness of video understanding .
- Evidence to watch: With the rapid advancement of video understanding , existing benchmarks are becoming increasingly saturated, exposing a critical discrepancy between inflated leaderboard scores and real-world model capabilities.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: Extensive experiments reveal a substantial gap between current best model Gemini-3-Pro and human experts, and uncover a clear hierarchical bottleneck where errors in visual information aggregation and...
- Approach: To address this widening gap, we introduce Video-MME-v2, a comprehensive benchmark designed to rigorously evaluate the robustness and faithfulness of video understanding .
- Result signal: With the rapid advancement of video understanding , existing benchmarks are becoming increasingly saturated, exposing a critical discrepancy between inflated leaderboard scores and real-world model...
- Community traction: Hugging Face Papers shows 93 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
Beyond Accuracy: Unveiling Inefficiency Patterns in Tool-Integrated Reasoning
TL;DR: Researchers introduce PTE (Prefill Token Equivalents), a hardware-aware metric for measuring efficiency in Tool-Integrated Reasoning scenarios, which better correlates with actual inference latency than traditional...
Researchers introduce PTE (Prefill Token Equivalents), a hardware-aware metric for measuring efficiency in Tool-Integrated Reasoning scenarios, which better correlates with actual inference latency than traditional token counts by accounting for KV-Cache inefficiencies and...
Researchers introduce PTE (Prefill Token Equivalents), a hardware-aware metric for measuring efficiency in Tool-Integrated Reasoning scenarios, which better correlates with actual inference latency than traditional token counts by accounting for KV-Cache...
Researchers introduce PTE (Prefill Token Equivalents), a hardware-aware metric for measuring efficiency in Tool-Integrated Reasoning scenarios, which better correlates with actual inference latency than traditional token counts by accounting for KV-Cache inefficiencies and long tool responses.
Researchers introduce PTE (Prefill Token Equivalents), a hardware-aware metric for measuring efficiency in Tool-Integrated Reasoning scenarios, which better correlates with actual inference latency than traditional token counts by accounting for KV-Cache inefficiencies and long tool responses.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: Researchers introduce PTE (Prefill Token Equivalents), a hardware-aware metric for measuring efficiency in Tool-Integrated Reasoning scenarios, which better correlates with actual inference latency than traditional token counts by...
- Method signal: Researchers introduce PTE (Prefill Token Equivalents), a hardware-aware metric for measuring efficiency in Tool-Integrated Reasoning scenarios, which better correlates with actual inference latency than traditional token counts by accounting...
- Evidence to watch: Researchers introduce PTE (Prefill Token Equivalents), a hardware-aware metric for measuring efficiency in Tool-Integrated Reasoning scenarios, which better correlates with actual inference latency than traditional token counts by...
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: Researchers introduce PTE (Prefill Token Equivalents), a hardware-aware metric for measuring efficiency in Tool-Integrated Reasoning scenarios, which better correlates with actual inference latency than...
- Approach: Researchers introduce PTE (Prefill Token Equivalents), a hardware-aware metric for measuring efficiency in Tool-Integrated Reasoning scenarios, which better correlates with actual inference latency than...
- Result signal: Researchers introduce PTE (Prefill Token Equivalents), a hardware-aware metric for measuring efficiency in Tool-Integrated Reasoning scenarios, which better correlates with actual inference latency...
- Community traction: Hugging Face Papers shows 22 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
Issue routing and exits.
The daily edition stays aligned with the rest of the site while keeping the full issue readable end to end.
Navigation
Public desks
Issue
- 04/08/2026
- 50 total analyzed
- Readable issue route