Daily Edition
The expanded edition keeps the full analyst notes, paper breakdowns, geopolitical framing, and the complete feed selected into this run.
Topic of the day.
A dedicated daily topic chosen from the strongest signals in the run, with TL;DR, why-now framing, and a fuller analyst read.
Enterprise AI deployment and adoption
TL;DR: Enterprise AI deployment and adoption is today's clearest AI theme: LightSeek Foundation Releases TokenSpeed, an Open-Source LLM Inference Engine Targeting TensorRT-LLM-Level Performance for Agentic Workloads leads the signal, and...
Why now: The topic shows up across MarkTechPost and BAIR Blog, The Decoder, which means the same operating pressure is appearing through multiple lenses instead of only one announcement.
Enterprise AI deployment and adoption deserves the slower read today because the supporting items cluster around agent, foundation, inference. LightSeek Foundation Releases TokenSpeed, an Open-Source LLM Inference Engine Targeting TensorRT-LLM-Level Performance for Agentic Workloads matters because it signals momentum in agent, foundation, inference and may shift how teams prioritize models, tooling, or deployment choices. The combined signal suggests teams should treat this as a real operating change rather...
- MarkTechPost: LightSeek Foundation Releases TokenSpeed, an Open-Source LLM Inference Engine Targeting TensorRT-LLM-Level Performance for Agentic Workloads points to LightSeek Foundation Releases TokenSpeed, an...
- BAIR Blog: Adaptive Parallel Reasoning: The Next Paradigm in Efficient Inference Scaling points to Adaptive Parallel Reasoning: The Next Paradigm in Efficient Inference Scaling matters because it signals momentum in...
- The Decoder: OpenAI's new voice model brings GPT-5-level reasoning to real-time conversations points to OpenAI's new voice model brings GPT-5-level reasoning to real-time conversations matters because it signals...
- LightSeek Foundation Releases TokenSpeed, an Open-Source LLM Inference Engine Targeting TensorRT-LLM-Level Performance for Agentic Workloads (MarkTechPost | 2026-05-07)
- Adaptive Parallel Reasoning: The Next Paradigm in Efficient Inference Scaling (BAIR Blog | 2026-05-08)
- OpenAI's new voice model brings GPT-5-level reasoning to real-time conversations (The Decoder | 2026-05-07)
Policy, chips, capital, and power.
Industrial strategy, compute supply, export controls, and big-company positioning shaping the AI balance of power.

US government increases AI suppliers and rethinks Anthropic’s role
The US administration has added four more AI companies to its roster of favoured suppliers, with the Pentagon signing agreements with Microsoft, Reflection AI (which has yet to release a publicly-available model), Amazon, and Nvidia that mean their products can be used on...
US government increases AI suppliers and rethinks Anthropic’s role matters because it affects the policy, supply-chain, or security constraints around AI development, especially across government, model.
- Primary signals: government, model.
- Source context: AI News published or updated this item on 2026-05-06.
Supercomputer networking to accelerate large scale AI training
Supercomputer networking to accelerate large scale AI training OpenAI
Supercomputer networking to accelerate large scale AI training matters because it affects the policy, supply-chain, or security constraints around AI development, especially across compute, training.
- Primary signals: compute, training.
- Source context: OpenAI Research published or updated this item on 2026-05-05.
Gradient-based Planning for World Models at Longer Horizons
GRASP is a new gradient-based planner for learned dynamics (a “world model”) that makes long-horizon planning practical by (1) lifting the trajectory into virtual states so optimization is parallel across time, (2) adding stochasticity directly to the state iterates for...
Gradient-based Planning for World Models at Longer Horizons matters because it affects the policy, supply-chain, or security constraints around AI development, especially across state, model.
- Primary signals: state, model.
- Source context: BAIR Blog published or updated this item on 2026-04-20.

SAP: How enterprise AI governance secures profit margins
According to SAP, enterprise AI governance secures profit margins by replacing statistical guesses with deterministic control. Ask a consumer-grade model to count the words in a document, and it will often miss the mark by ten percent. Manos Raptopoulos, Global President of...
SAP: How enterprise AI governance secures profit margins matters because it affects the policy, supply-chain, or security constraints around AI development, especially across europe, model.
- Primary signals: europe, model.
- Source context: AI News published or updated this item on 2026-05-01.

Weekly Top Picks #120
Q1 earnings / Trump wants to nationalize AI / China protects its workers / ARC-AGI-3 defeats GPT-5.5 and Opus-4.7 / The "permanent underclass" / Dawkins x Claudia
Weekly Top Picks #120 matters because it affects the policy, supply-chain, or security constraints around AI development, especially across china, gpt.
- Primary signals: china, gpt.
- Source context: The Algorithmic Bridge published or updated this item on 2026-05-01.
Product, model, and platform movement.
Software, model, deployment, and competitive stories with the strongest operator and market signal in this edition.
LightSeek Foundation Releases TokenSpeed, an Open-Source LLM Inference Engine Targeting TensorRT-LLM-Level Performance for Agentic Workloads
LightSeek Foundation Releases TokenSpeed, an Open-Source LLM Inference Engine Targeting TensorRT-LLM-Level Performance for Agentic Workloads MarkTechPost
LightSeek Foundation Releases TokenSpeed, an Open-Source LLM Inference Engine Targeting TensorRT-LLM-Level Performance for Agentic Workloads matters because it signals momentum in agent, foundation, inference and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, foundation, inference.
- Source context: MarkTechPost published or updated this item on 2026-05-07.
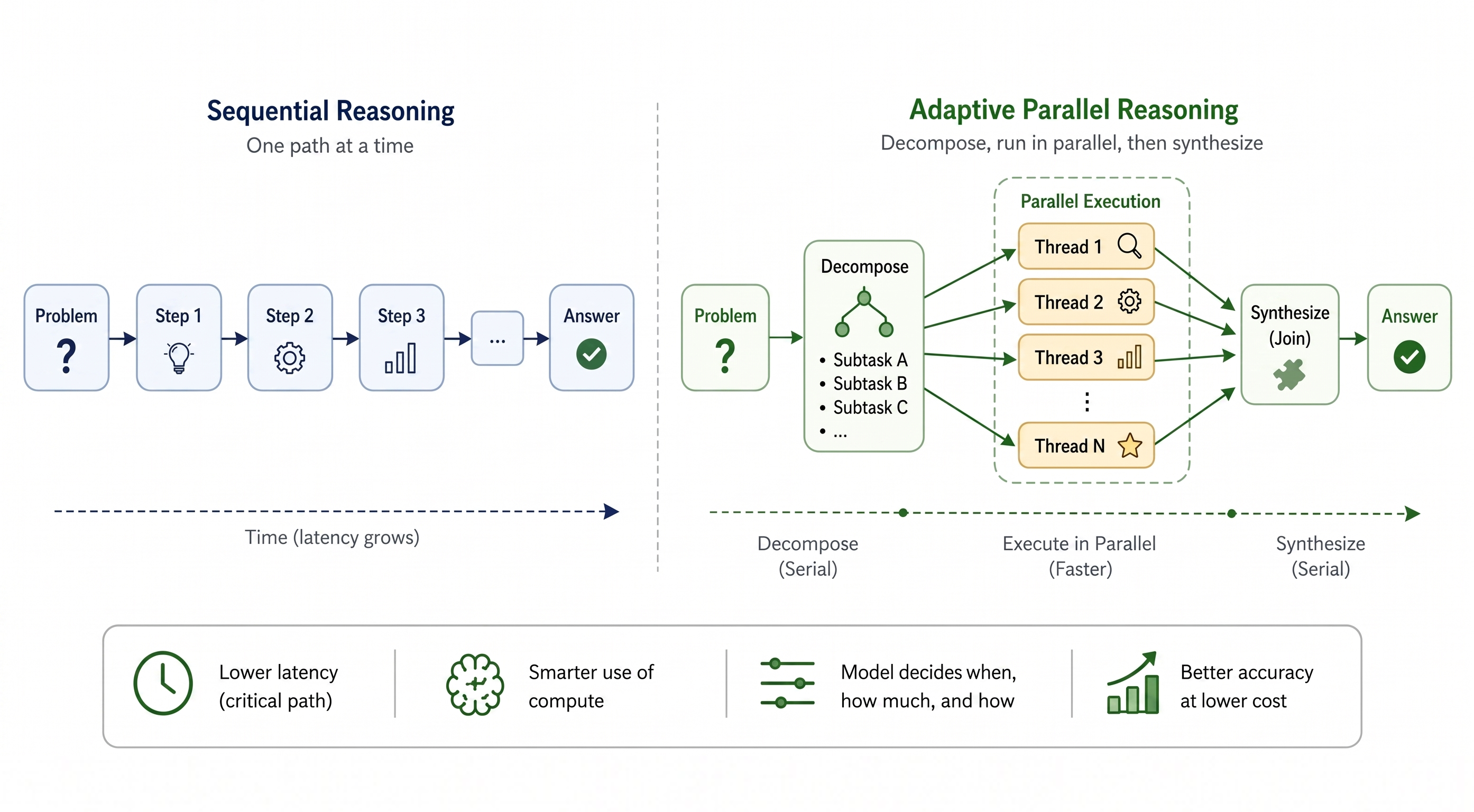
Adaptive Parallel Reasoning: The Next Paradigm in Efficient Inference Scaling
Overview of adaptive parallel reasoning. What if a reasoning model could decide for itself when to decompose and parallelize independent subtasks, how many concurrent threads to spawn, and how to coordinate them based on the problem at hand? We provide a detailed analysis of...
Adaptive Parallel Reasoning: The Next Paradigm in Efficient Inference Scaling matters because it signals momentum in inference, model, reasoning and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: inference, model, reasoning.
- Source context: BAIR Blog published or updated this item on 2026-05-08.
OpenAI's new voice model brings GPT-5-level reasoning to real-time conversations
OpenAI's new voice model brings GPT-5-level reasoning to real-time conversations the-decoder.com
OpenAI's new voice model brings GPT-5-level reasoning to real-time conversations matters because it signals momentum in gpt, model, reasoning and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: gpt, model, reasoning.
- Source context: The Decoder published or updated this item on 2026-05-07.
Claude's new "Dreaming" feature is designed to let AI agents learn from their mistakes
Claude's new "Dreaming" feature is designed to let AI agents learn from their mistakes the-decoder.com
Claude's new "Dreaming" feature is designed to let AI agents learn from their mistakes matters because it signals momentum in agent, agents and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, agents.
- Source context: The Decoder published or updated this item on 2026-05-07.

CyberSecQwen-4B: Why Defensive Cyber Needs Small, Specialized, Locally-Runnable Models
A Blog post by Lablab.ai AMD Developer Hackathon on Hugging Face
CyberSecQwen-4B: Why Defensive Cyber Needs Small, Specialized, Locally-Runnable Models matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: Hugging Face Blog published or updated this item on 2026-05-08.
Differentiated source coverage.
Stories drawn from research blogs, first-party lab posts, practitioner newsletters, and selected technical outlets so the edition does not mirror the same headline across every source.
Adaptive Parallel Reasoning: The Next Paradigm in Efficient Inference Scaling
Overview of adaptive parallel reasoning. What if a reasoning model could decide for itself when to decompose and parallelize independent subtasks, how many concurrent threads to spawn, and how to coordinate them based on the problem at hand? We provide a detailed analysis of...
Adaptive Parallel Reasoning: The Next Paradigm in Efficient Inference Scaling matters because it signals momentum in inference, model, reasoning and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: inference, model, reasoning.
- Source context: BAIR Blog published or updated this item on 2026-05-08.

EMO: Pretraining mixture of experts for emergent modularity
A Blog post by Ai2 on Hugging Face
EMO: Pretraining mixture of experts for emergent modularity matters because it signals momentum in training and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: training.
- Source context: Hugging Face Blog published or updated this item on 2026-05-08.
Advancing voice intelligence with new models in the API
Advancing voice intelligence with new models in the API OpenAI
Advancing voice intelligence with new models in the API matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: OpenAI Research published or updated this item on 2026-05-07.
Donating our open-source alignment tool
Donating our open-source alignment tool Anthropic
Donating our open-source alignment tool matters because it signals momentum in alignment and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: alignment.
- Source context: Anthropic Research published or updated this item on 2026-05-07.

Decoupled DiLoCo: A new frontier for resilient, distributed AI training
Googleâs new distributed architecture keeps AI training runs on track across distant data centers, with exceptional efficiency â even when hardware fails.
Decoupled DiLoCo: A new frontier for resilient, distributed AI training matters because it signals momentum in frontier, training and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: frontier, training.
- Source context: DeepMind Blog published or updated this item on 2026-04-22.
Build a Modular Skill-Based Agent System for LLMs with Dynamic Tool Routing in Python
Build a Modular Skill-Based Agent System for LLMs with Dynamic Tool Routing in Python MarkTechPost
Build a Modular Skill-Based Agent System for LLMs with Dynamic Tool Routing in Python matters because it signals momentum in agent, llm and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, llm.
- Source context: MarkTechPost published or updated this item on 2026-05-05.

HP and the art of AI and data for the enterprise
Ahead of the AI & Big Data Expo at the San Jose McEnery Convention Center, May 18-19, we spoke to Jerome Gabryszewski, the company’s AI & Data Science Business Development Manager about AI, processing data for AI ingestion, and local versus cloud compute. The technology media...
HP and the art of AI and data for the enterprise matters because it affects the policy, supply-chain, or security constraints around AI development, especially across compute.
- Primary signals: compute.
- Source context: AI News published or updated this item on 2026-05-06.
IBM & Oracle Expand Partnership to Help Enterprise Scale AI
IBM & Oracle Expand Partnership to Help Enterprise Scale AI AI Magazine
IBM & Oracle Expand Partnership to Help Enterprise Scale AI matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: AI Magazine published or updated this item on 2026-05-08.
Method, limitations, and results.
Paper summaries, methodology notes, limitations, and deep-dive bullets for the research items selected into the digest.

Skill1: Unified Evolution of Skill-Augmented Agents via Reinforcement Learning
TL;DR: Skill1 is a unified framework that trains a single policy to simultaneously evolve skill selection, utilization, and distillation capabilities using a shared task-outcome objective, demonstrating superior performance...
Skill1 is a unified framework that trains a single policy to simultaneously evolve skill selection, utilization, and distillation capabilities using a shared task-outcome objective, demonstrating superior performance over existing baselines in complex task environments. A...
Skill1 is a unified framework that trains a single policy to simultaneously evolve skill selection, utilization, and distillation capabilities using a shared task-outcome objective, demonstrating superior performance over existing baselines in complex task...
We propose Skill1, a framework that trains a single policy to co-evolve skill selection , utilization, and distillation toward a shared task-outcome objective .
Skill1 is a unified framework that trains a single policy to simultaneously evolve skill selection, utilization, and distillation capabilities using a shared task-outcome objective, demonstrating superior performance over existing baselines in complex task environments.
The reported improvement still needs a closer check on benchmark scope, ablations, and whether the method keeps working outside the authors' evaluation setup.
- Problem framing: Skill1 is a unified framework that trains a single policy to simultaneously evolve skill selection, utilization, and distillation capabilities using a shared task-outcome objective, demonstrating superior performance over existing...
- Method signal: We propose Skill1, a framework that trains a single policy to co-evolve skill selection , utilization, and distillation toward a shared task-outcome objective .
- Evidence to watch: Skill1 is a unified framework that trains a single policy to simultaneously evolve skill selection, utilization, and distillation capabilities using a shared task-outcome objective, demonstrating superior performance over existing...
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: Skill1 is a unified framework that trains a single policy to simultaneously evolve skill selection, utilization, and distillation capabilities using a shared task-outcome objective, demonstrating superior...
- Approach: We propose Skill1, a framework that trains a single policy to co-evolve skill selection , utilization, and distillation toward a shared task-outcome objective .
- Result signal: Skill1 is a unified framework that trains a single policy to simultaneously evolve skill selection, utilization, and distillation capabilities using a shared task-outcome objective, demonstrating...
- Community traction: Hugging Face Papers shows 52 votes for this paper.
- The reported improvement still needs a closer check on benchmark scope, ablations, and whether the method keeps working outside the authors' evaluation setup.

Benchmarking Egocentric Multimodal Goal Inference for Assistive Wearable Agents
TL;DR: There has recently been a surge of interest in Wearable Assistant Agents: agents embodied in a wearable form factor such as smart glasses, who can take actions toward a user’s stated goal — a high-level...
There has recently been a surge of interest in Wearable Assistant Agents: agents embodied in a wearable form factor such as smart glasses, who can take actions toward a user’s stated goal — a high-level language-expressed command such as “where did I leave my keys?”, “Text...
There has recently been a surge of interest in Wearable Assistant Agents: agents embodied in a wearable form factor such as smart glasses, who can take actions toward a user’s stated goal — a high-level language-expressed command such as “where did I leave...
However, MCQ assesses discrimination, not the model’s ultimate task of generating the goal through open-ended text generation.
We ran a human predictability study, where we found that humans set a strong baseline that comprises a de facto upper bound on model performance: they show multiple choice question (MCQ) accuracy of 93%, with the best VLM achieving about 84% accuracy.
The abstract is promising, but we still need to inspect the full paper for compute cost, implementation complexity, and how broadly the gains transfer beyond the reported benchmarks.
- Problem framing: There has recently been a surge of interest in Wearable Assistant Agents: agents embodied in a wearable form factor such as smart glasses, who can take actions toward a user’s stated goal — a high-level language-expressed command such as...
- Method signal: However, MCQ assesses discrimination, not the model’s ultimate task of generating the goal through open-ended text generation.
- Evidence to watch: We ran a human predictability study, where we found that humans set a strong baseline that comprises a de facto upper bound on model performance: they show multiple choice question (MCQ) accuracy of 93%, with the best VLM achieving about...
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from NeurIPS 2025.
- Problem: There has recently been a surge of interest in Wearable Assistant Agents: agents embodied in a wearable form factor such as smart glasses, who can take actions toward a user’s stated goal — a high-level...
- Approach: However, MCQ assesses discrimination, not the model’s ultimate task of generating the goal through open-ended text generation.
- Result signal: We ran a human predictability study, where we found that humans set a strong baseline that comprises a de facto upper bound on model performance: they show multiple choice question (MCQ) accuracy of...
- Conference context: NeurIPS 2025 Datasets and Benchmarks Track
- The abstract is promising, but we still need to inspect the full paper for compute cost, implementation complexity, and how broadly the gains transfer beyond the reported benchmarks.

Improve Temporal Reasoning in Multimodal Large Language Models via Video Contrastive Decoding
TL;DR: A major distinction between video and image understanding is that the former requires reasoning over time.
A major distinction between video and image understanding is that the former requires reasoning over time. Existing Video Large Language Models (VLLMs) demonstrate promising performance in general video understanding, such as brief captioning or object recognition within...
A major distinction between video and image understanding is that the former requires reasoning over time.
Such corruption induces time-insensitive wrong responses from the model, which are then contrastively avoided when generating the final correct output.
Existing Video Large Language Models (VLLMs) demonstrate promising performance in general video understanding, such as brief captioning or object recognition within individual frames.
The abstract is promising, but we still need to inspect the full paper for compute cost, implementation complexity, and how broadly the gains transfer beyond the reported benchmarks.
- Problem framing: A major distinction between video and image understanding is that the former requires reasoning over time.
- Method signal: Such corruption induces time-insensitive wrong responses from the model, which are then contrastively avoided when generating the final correct output.
- Evidence to watch: Existing Video Large Language Models (VLLMs) demonstrate promising performance in general video understanding, such as brief captioning or object recognition within individual frames.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from NeurIPS 2025.
- Problem: A major distinction between video and image understanding is that the former requires reasoning over time.
- Approach: Such corruption induces time-insensitive wrong responses from the model, which are then contrastively avoided when generating the final correct output.
- Result signal: Existing Video Large Language Models (VLLMs) demonstrate promising performance in general video understanding, such as brief captioning or object recognition within individual frames.
- Conference context: NeurIPS 2025 Main Conference Track
- The abstract is promising, but we still need to inspect the full paper for compute cost, implementation complexity, and how broadly the gains transfer beyond the reported benchmarks.

MLLM-For3D: Adapting Multimodal Large Language Model for 3D Reasoning Segmentation
TL;DR: Reasoning segmentation aims to segment target objects in complex scenes based on human intent and spatial reasoning.
Reasoning segmentation aims to segment target objects in complex scenes based on human intent and spatial reasoning. While recent multimodal large language models (MLLMs) have demonstrated impressive 2D image reasoning segmentation, adapting these capabilities to 3D scenes...
The primary challenge lies in the absence of 3D context and spatial consistency across multiple views, causing the model to hallucinate objects that do not exist and fail to target objects consistently.
In this paper, we introduce MLLM-For3D, a simple yet effective framework that transfers knowledge from 2D MLLMs to 3D scene understanding.
While recent multimodal large language models (MLLMs) have demonstrated impressive 2D image reasoning segmentation, adapting these capabilities to 3D scenes remains underexplored.
The abstract is promising, but we still need to inspect the full paper for compute cost, implementation complexity, and how broadly the gains transfer beyond the reported benchmarks.
- Problem framing: The primary challenge lies in the absence of 3D context and spatial consistency across multiple views, causing the model to hallucinate objects that do not exist and fail to target objects consistently.
- Method signal: In this paper, we introduce MLLM-For3D, a simple yet effective framework that transfers knowledge from 2D MLLMs to 3D scene understanding.
- Evidence to watch: While recent multimodal large language models (MLLMs) have demonstrated impressive 2D image reasoning segmentation, adapting these capabilities to 3D scenes remains underexplored.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from NeurIPS 2025.
- Problem: The primary challenge lies in the absence of 3D context and spatial consistency across multiple views, causing the model to hallucinate objects that do not exist and fail to target objects consistently.
- Approach: In this paper, we introduce MLLM-For3D, a simple yet effective framework that transfers knowledge from 2D MLLMs to 3D scene understanding.
- Result signal: While recent multimodal large language models (MLLMs) have demonstrated impressive 2D image reasoning segmentation, adapting these capabilities to 3D scenes remains underexplored.
- Conference context: NeurIPS 2025 Main Conference Track
- The abstract is promising, but we still need to inspect the full paper for compute cost, implementation complexity, and how broadly the gains transfer beyond the reported benchmarks.

ReCAP: Recursive Context-Aware Reasoning and Planning for Large Language Model Agents
TL;DR: Long-horizon tasks requiring multi-step reasoning and dynamic re-planning remain challenging for large language models (LLMs).
Long-horizon tasks requiring multi-step reasoning and dynamic re-planning remain challenging for large language models (LLMs). Sequential prompting methods are prone to context drift, loss of goal information, and recurrent failure cycles, while hierarchical prompting methods...
Long-horizon tasks requiring multi-step reasoning and dynamic re-planning remain challenging for large language models (LLMs).
We introduce ReCAP (Recursive Context-Aware Reasoning and Planning), a hierarchical framework with shared context for reasoning and planning in LLMs.
Experiments demonstrate that ReCAP substantially improves subgoal alignment and success rates on various long-horizon reasoning benchmarks, achieving a 32\% gain on synchronous Robotouille and a 29\% improvement on asynchronous Robotouille under the strict pass@1 protocol.
The abstract is promising, but we still need to inspect the full paper for compute cost, implementation complexity, and how broadly the gains transfer beyond the reported benchmarks.
- Problem framing: Long-horizon tasks requiring multi-step reasoning and dynamic re-planning remain challenging for large language models (LLMs).
- Method signal: We introduce ReCAP (Recursive Context-Aware Reasoning and Planning), a hierarchical framework with shared context for reasoning and planning in LLMs.
- Evidence to watch: Experiments demonstrate that ReCAP substantially improves subgoal alignment and success rates on various long-horizon reasoning benchmarks, achieving a 32\% gain on synchronous Robotouille and a 29\% improvement on asynchronous...
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from NeurIPS 2025.
- Problem: Long-horizon tasks requiring multi-step reasoning and dynamic re-planning remain challenging for large language models (LLMs).
- Approach: We introduce ReCAP (Recursive Context-Aware Reasoning and Planning), a hierarchical framework with shared context for reasoning and planning in LLMs.
- Result signal: Experiments demonstrate that ReCAP substantially improves subgoal alignment and success rates on various long-horizon reasoning benchmarks, achieving a 32\% gain on synchronous Robotouille and a 29\%...
- Conference context: NeurIPS 2025 Main Conference Track
- The abstract is promising, but we still need to inspect the full paper for compute cost, implementation complexity, and how broadly the gains transfer beyond the reported benchmarks.
Everything selected into the run.
The complete analyzed stream for the issue, useful when you want to scan the entire run instead of only the curated front page.
LightSeek Foundation Releases TokenSpeed, an Open-Source LLM Inference Engine Targeting TensorRT-LLM-Level Performance for Agentic Workloads
LightSeek Foundation Releases TokenSpeed, an Open-Source LLM Inference Engine Targeting TensorRT-LLM-Level Performance for Agentic Workloads MarkTechPost
LightSeek Foundation Releases TokenSpeed, an Open-Source LLM Inference Engine Targeting TensorRT-LLM-Level Performance for Agentic Workloads matters because it signals momentum in agent, foundation, inference and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, foundation, inference.
- Source context: MarkTechPost published or updated this item on 2026-05-07.
Adaptive Parallel Reasoning: The Next Paradigm in Efficient Inference Scaling
Overview of adaptive parallel reasoning. What if a reasoning model could decide for itself when to decompose and parallelize independent subtasks, how many concurrent threads to spawn, and how to coordinate them based on the problem at hand? We provide a detailed analysis of...
Adaptive Parallel Reasoning: The Next Paradigm in Efficient Inference Scaling matters because it signals momentum in inference, model, reasoning and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: inference, model, reasoning.
- Source context: BAIR Blog published or updated this item on 2026-05-08.
OpenAI's new voice model brings GPT-5-level reasoning to real-time conversations
OpenAI's new voice model brings GPT-5-level reasoning to real-time conversations the-decoder.com
OpenAI's new voice model brings GPT-5-level reasoning to real-time conversations matters because it signals momentum in gpt, model, reasoning and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: gpt, model, reasoning.
- Source context: The Decoder published or updated this item on 2026-05-07.
Claude's new "Dreaming" feature is designed to let AI agents learn from their mistakes
Claude's new "Dreaming" feature is designed to let AI agents learn from their mistakes the-decoder.com
Claude's new "Dreaming" feature is designed to let AI agents learn from their mistakes matters because it signals momentum in agent, agents and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, agents.
- Source context: The Decoder published or updated this item on 2026-05-07.
CyberSecQwen-4B: Why Defensive Cyber Needs Small, Specialized, Locally-Runnable Models
A Blog post by Lablab.ai AMD Developer Hackathon on Hugging Face
CyberSecQwen-4B: Why Defensive Cyber Needs Small, Specialized, Locally-Runnable Models matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: Hugging Face Blog published or updated this item on 2026-05-08.
EMO: Pretraining mixture of experts for emergent modularity
A Blog post by Ai2 on Hugging Face
EMO: Pretraining mixture of experts for emergent modularity matters because it signals momentum in training and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: training.
- Source context: Hugging Face Blog published or updated this item on 2026-05-08.

Introducing NVIDIA Nemotron 3 Nano Omni: Long-Context Multimodal Intelligence for Documents, Audio and Video Agents
A Blog post by NVIDIA on Hugging Face
Introducing NVIDIA Nemotron 3 Nano Omni: Long-Context Multimodal Intelligence for Documents, Audio and Video Agents matters because it signals momentum in agent, agents, multimodal and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, agents, multimodal.
- Source context: Hugging Face Blog published or updated this item on 2026-04-28.

Physical AI raises governance questions for autonomous systems
Governance around Physical AI is becoming harder as autonomous AI systems move into robots, sensors, and industrial equipment. The issue is not only whether AI agents can complete tasks. It is how their actions are tested, monitored, and stopped when they interact with...
Physical AI raises governance questions for autonomous systems matters because it signals momentum in agent, agents, robotics and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, agents, robotics.
- Source context: AI News published or updated this item on 2026-05-04.
Advancing voice intelligence with new models in the API
Advancing voice intelligence with new models in the API OpenAI
Advancing voice intelligence with new models in the API matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: OpenAI Research published or updated this item on 2026-05-07.
Donating our open-source alignment tool
Donating our open-source alignment tool Anthropic
Donating our open-source alignment tool matters because it signals momentum in alignment and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: alignment.
- Source context: Anthropic Research published or updated this item on 2026-05-07.
Scaling Trusted Access for Cyber with GPT-5.5 and GPT-5.5-Cyber
Scaling Trusted Access for Cyber with GPT-5.5 and GPT-5.5-Cyber OpenAI
Scaling Trusted Access for Cyber with GPT-5.5 and GPT-5.5-Cyber matters because it signals momentum in gpt and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: gpt.
- Source context: OpenAI Research published or updated this item on 2026-05-07.
IBM & Oracle Expand Partnership to Help Enterprise Scale AI
IBM & Oracle Expand Partnership to Help Enterprise Scale AI AI Magazine
IBM & Oracle Expand Partnership to Help Enterprise Scale AI matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: AI Magazine published or updated this item on 2026-05-08.

RingCentral adds Shopify, Calendly, and WhatsApp to AI Receptionist
RingCentral has expanded its AI Receptionist product with new links to Shopify, Calendly and WhatsApp, as the communications software company tries to push the product beyond basic call answering and into more routine customer service tasks. The company said AI Receptionist,...
RingCentral adds Shopify, Calendly, and WhatsApp to AI Receptionist matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: AI News published or updated this item on 2026-05-08.
Anthropic ships ten AI agents for finance as both it and OpenAI chase IPO-ready revenue
Anthropic ships ten AI agents for finance as both it and OpenAI chase IPO-ready revenue the-decoder.com
Anthropic ships ten AI agents for finance as both it and OpenAI chase IPO-ready revenue matters because it signals momentum in agent, agents and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, agents.
- Source context: The Decoder published or updated this item on 2026-05-05.
Build a Modular Skill-Based Agent System for LLMs with Dynamic Tool Routing in Python
Build a Modular Skill-Based Agent System for LLMs with Dynamic Tool Routing in Python MarkTechPost
Build a Modular Skill-Based Agent System for LLMs with Dynamic Tool Routing in Python matters because it signals momentum in agent, llm and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent, llm.
- Source context: MarkTechPost published or updated this item on 2026-05-05.
Last Week in AI #340 - OpenAI vs Musk + Microsoft, DeepSeek v4, Vision Banana
First week of Musk v. Altman, OpenAI ends Microsoft legal peril over its $50B Amazon deal, DeepSeek previews new AI model that ‘closes the gap’ with frontier models, and more!
Last Week in AI #340 - OpenAI vs Musk + Microsoft, DeepSeek v4, Vision Banana matters because it signals momentum in frontier, model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: frontier, model.
- Source context: Last Week in AI published or updated this item on 2026-05-05.
Decoupled DiLoCo: A new frontier for resilient, distributed AI training
Googleâs new distributed architecture keeps AI training runs on track across distant data centers, with exceptional efficiency â even when hardware fails.
Decoupled DiLoCo: A new frontier for resilient, distributed AI training matters because it signals momentum in frontier, training and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: frontier, training.
- Source context: DeepMind Blog published or updated this item on 2026-04-22.

Announcing our partnership with the Republic of Korea
Google DeepMind and Korea partner to accelerate scientific breakthroughs using frontier AI models
Announcing our partnership with the Republic of Korea matters because it signals momentum in frontier, model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: frontier, model.
- Source context: DeepMind Blog published or updated this item on 2026-04-27.
LWiAI Podcast #242 - ChatGPT Images 2.0, Qwen 3.6 Max, Kimi-K2.6
ChatGPT’s new Images 2.0 model is surprisingly good at generating text , Alibaba Drops Qwen 3.6 Max Preview , SpaceX is working with Cursor
LWiAI Podcast #242 - ChatGPT Images 2.0, Qwen 3.6 Max, Kimi-K2.6 matters because it signals momentum in gpt, model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: gpt, model.
- Source context: Last Week in AI published or updated this item on 2026-04-30.
LWiAI Podcast #243 - GPT 5.5, DeepSeek V4, AI safety sabotage
Our 243rd episode with a summary and discussion of last week’s big AI news!
LWiAI Podcast #243 - GPT 5.5, DeepSeek V4, AI safety sabotage matters because it signals momentum in gpt, safety and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: gpt, safety.
- Source context: Last Week in AI published or updated this item on 2026-05-04.

AlphaEvolve: How our Gemini-powered coding agent is scaling impact across fields
Explore how AlphaEvolve's Gemini-powered algorithms are driving impact across business, infrastructure, and science.
AlphaEvolve: How our Gemini-powered coding agent is scaling impact across fields matters because it signals momentum in agent and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent.
- Source context: DeepMind Blog published or updated this item on 2026-05-06.
Google AI Releases Multi-Token Prediction (MTP) Drafters for Gemma 4: Delivering Up to 3x Faster Inference Without Quality Loss
Google AI Releases Multi-Token Prediction (MTP) Drafters for Gemma 4: Delivering Up to 3x Faster Inference Without Quality Loss MarkTechPost
Google AI Releases Multi-Token Prediction (MTP) Drafters for Gemma 4: Delivering Up to 3x Faster Inference Without Quality Loss matters because it signals momentum in inference and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: inference.
- Source context: MarkTechPost published or updated this item on 2026-05-06.

Google tests Remy AI agent for Gemini as focus turns to user control
Google is testing Remy, a new AI personal agent for Gemini, according to Business Insider. The tool is designed to take actions for users in work and daily tasks. Remy is being tested in a staff-only version of the Gemini app. The report said it reviewed an internal document...
Google tests Remy AI agent for Gemini as focus turns to user control matters because it signals momentum in agent and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent.
- Source context: AI News published or updated this item on 2026-05-06.
Introducing ChatGPT Futures: Class of 2026
Introducing ChatGPT Futures: Class of 2026 OpenAI
Introducing ChatGPT Futures: Class of 2026 matters because it signals momentum in gpt and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: gpt.
- Source context: OpenAI Research published or updated this item on 2026-05-06.
Introducing Trusted Contact in ChatGPT
Introducing Trusted Contact in ChatGPT OpenAI
Introducing Trusted Contact in ChatGPT matters because it signals momentum in gpt and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: gpt.
- Source context: OpenAI Research published or updated this item on 2026-05-06.
Inworld AI Launches Realtime TTS-2: A Closed-Loop Voice Model That Adapts to How You Actually Talk
Inworld AI Launches Realtime TTS-2: A Closed-Loop Voice Model That Adapts to How You Actually Talk MarkTechPost
Inworld AI Launches Realtime TTS-2: A Closed-Loop Voice Model That Adapts to How You Actually Talk matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: MarkTechPost published or updated this item on 2026-05-06.

vLLM V0 to V1: Correctness Before Corrections in RL
A Blog post by ServiceNow-AI on Hugging Face
vLLM V0 to V1: Correctness Before Corrections in RL matters because it signals momentum in llm and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: llm.
- Source context: Hugging Face Blog published or updated this item on 2026-05-06.
AI helping ease the UK’s NHS burden
The words “pressure” and “NHS” go hand in hand in the UK and unfortunately there is no sign of a reduction in the strain the institution suffers any time soon. As NHS England continues the struggle to reduce its 7.25 million waiting list, new policies are being introduced to...
AI helping ease the UK’s NHS burden matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: AI News published or updated this item on 2026-05-07.

Elon Musk, Kingmaker
The AI race has been tilted in favor of Anthropic
Elon Musk, Kingmaker matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: The Algorithmic Bridge published or updated this item on 2026-05-07.
Focus areas for The Anthropic Institute
Focus areas for The Anthropic Institute Anthropic
Focus areas for The Anthropic Institute matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Anthropic Research published or updated this item on 2026-05-07.
Google Reduces Water Stress with AI Precision Agriculture
Google Reduces Water Stress with AI Precision Agriculture AI Magazine
Google Reduces Water Stress with AI Precision Agriculture matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: AI Magazine published or updated this item on 2026-05-07.
Natural Language Autoencoders: Turning Claude’s thoughts into text
Natural Language Autoencoders: Turning Claude’s thoughts into text Anthropic
Natural Language Autoencoders: Turning Claude’s thoughts into text matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Anthropic Research published or updated this item on 2026-05-07.
ChatGPT update rolls out GPT-5.5 Instant with fewer hallucinations and more personalized answers
ChatGPT update rolls out GPT-5.5 Instant with fewer hallucinations and more personalized answers the-decoder.com
ChatGPT update rolls out GPT-5.5 Instant with fewer hallucinations and more personalized answers matters because it signals momentum in gpt and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: gpt.
- Source context: The Decoder published or updated this item on 2026-05-05.

Partnering with industry leaders to accelerate AI transformation
Google DeepMind partners with global consultancies to bring the power of frontier AI to organizations around the world.
Partnering with industry leaders to accelerate AI transformation matters because it signals momentum in frontier and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: frontier.
- Source context: DeepMind Blog published or updated this item on 2026-04-21.

Weekly Top Picks #119
SpaceX + Cursor + Mistral / Jensen v Jensen / The job AI can't take / GPT-5.5 and ChatGPT Images 2.0 / An anti-grammar app / Terence Tao on the future
Weekly Top Picks #119 matters because it signals momentum in gpt and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: gpt.
- Source context: The Algorithmic Bridge published or updated this item on 2026-04-24.

DeepInfra on Hugging Face Inference Providers 🔥
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
DeepInfra on Hugging Face Inference Providers 🔥 matters because it signals momentum in inference and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: inference.
- Source context: Hugging Face Blog published or updated this item on 2026-04-29.

Granite 4.1 LLMs: How They’re Built
A Blog post by IBM Granite on Hugging Face
Granite 4.1 LLMs: How They’re Built matters because it signals momentum in llm and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: llm.
- Source context: Hugging Face Blog published or updated this item on 2026-04-29.

Enabling a new model for healthcare with AI co-clinician
Researching the path to AI-augmented care and development of an AI co-clinician.
Enabling a new model for healthcare with AI co-clinician matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: DeepMind Blog published or updated this item on 2026-04-30.
Moonshot AI Open-Sources FlashKDA: CUTLASS Kernels for Kimi Delta Attention with Variable-Length Batching and H20 Benchmarks
Moonshot AI Open-Sources FlashKDA: CUTLASS Kernels for Kimi Delta Attention with Variable-Length Batching and H20 Benchmarks MarkTechPost
Moonshot AI Open-Sources FlashKDA: CUTLASS Kernels for Kimi Delta Attention with Variable-Length Batching and H20 Benchmarks matters because it signals momentum in benchmark and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: benchmark.
- Source context: MarkTechPost published or updated this item on 2026-05-01.
Musk v. Altman week 1: Elon Musk says he was duped, warns AI could kill us all, and admits that xAI distills OpenAI’s models
Musk v. Altman week 1: Elon Musk says he was duped, warns AI could kill us all, and admits that xAI distills OpenAI’s models MIT Technology Review
Musk v. Altman week 1: Elon Musk says he was duped, warns AI could kill us all, and admits that xAI distills OpenAI’s models matters because it signals momentum in model and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: model.
- Source context: MIT Tech Review AI published or updated this item on 2026-05-01.
OpenAI Cracks Down on Talk of Goblins in ChatGPT
OpenAI Cracks Down on Talk of Goblins in ChatGPT AI Magazine
OpenAI Cracks Down on Talk of Goblins in ChatGPT matters because it signals momentum in gpt and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: gpt.
- Source context: AI Magazine published or updated this item on 2026-05-01.

Google made agentic AI governance a product. Enterprises still have to catch up.
Two weeks ago at Google Cloud Next ’26 in Las Vegas, Google did something the enterprise AI industry has been dancing around for the better part of two years: it made agentic AI governance a native product feature, not an afterthought. The centrepiece announcement was the...
Google made agentic AI governance a product. Enterprises still have to catch up. matters because it signals momentum in agent and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: agent.
- Source context: AI News published or updated this item on 2026-05-04.

Adding Benchmaxxer Repellant to the Open ASR Leaderboard
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Adding Benchmaxxer Repellant to the Open ASR Leaderboard matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Hugging Face Blog published or updated this item on 2026-05-06.

How the AI Industry Runs on Its Own Money
It will end really well or really badly
How the AI Industry Runs on Its Own Money matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: The Algorithmic Bridge published or updated this item on 2026-05-06.
A blueprint for using AI to strengthen democracy
A blueprint for using AI to strengthen democracy MIT Technology Review
A blueprint for using AI to strengthen democracy matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: MIT Tech Review AI published or updated this item on 2026-05-05.
AI 101: Gemma 4 and Why Many OpenClaw Users are Now Switching to it
AI 101: Gemma 4 and Why Many OpenClaw Users are Now Switching to it Turing Post
AI 101: Gemma 4 and Why Many OpenClaw Users are Now Switching to it matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Turing Post published or updated this item on 2026-04-09.
🎙️"Intention is what we need": Neeru Khosla on the Future of Education and Learning with AI
🎙️"Intention is what we need": Neeru Khosla on the Future of Education and Learning with AI Turing Post
🎙️"Intention is what we need": Neeru Khosla on the Future of Education and Learning with AI matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Turing Post published or updated this item on 2026-04-18.

How the AI Writing Panic Is Making Us All Worse Writers
This applies to those who use AI to write and those who don’t
How the AI Writing Panic Is Making Us All Worse Writers matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: The Algorithmic Bridge published or updated this item on 2026-04-21.
The era of AI malaise
The era of AI malaise MIT Technology Review
The era of AI malaise matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: MIT Tech Review AI published or updated this item on 2026-04-21.
Loop’s AI Logistics Data Platform Gets US$95m Funding
Loop’s AI Logistics Data Platform Gets US$95m Funding AI Magazine
Loop’s AI Logistics Data Platform Gets US$95m Funding matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: AI Magazine published or updated this item on 2026-04-23.
Why Uber has Already Burned Through its AI Budget
Why Uber has Already Burned Through its AI Budget AI Magazine
Why Uber has Already Burned Through its AI Budget matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: AI Magazine published or updated this item on 2026-04-23.

How to build scalable web apps with OpenAI's Privacy Filter
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
How to build scalable web apps with OpenAI's Privacy Filter matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Hugging Face Blog published or updated this item on 2026-04-27.
AI 101: What’s So Magical About Embeddings?
AI 101: What’s So Magical About Embeddings? Turing Post
AI 101: What’s So Magical About Embeddings? matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Turing Post published or updated this item on 2026-04-29.
Evaluating Claude’s bioinformatics research capabilities with BioMysteryBench
Evaluating Claude’s bioinformatics research capabilities with BioMysteryBench Anthropic
Evaluating Claude’s bioinformatics research capabilities with BioMysteryBench matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Anthropic Research published or updated this item on 2026-04-29.

This Is the Worst Career Decision You Can Make Right Now
New research from the US Federal Reserve provides a clear answer
This Is the Worst Career Decision You Can Make Right Now matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: The Algorithmic Bridge published or updated this item on 2026-04-29.
How people ask Claude for personal guidance
How people ask Claude for personal guidance Anthropic
How people ask Claude for personal guidance matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Anthropic Research published or updated this item on 2026-04-30.
FOD#151: Recursive Self-Learning: Why It Matters Now
FOD#151: Recursive Self-Learning: Why It Matters Now Turing Post
FOD#151: Recursive Self-Learning: Why It Matters Now matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: Turing Post published or updated this item on 2026-05-04.

How to Get More From AI by Using Fewer Tools
Don’t fall for the tool sprawl trap
How to Get More From AI by Using Fewer Tools matters because it signals momentum in the broader AI ecosystem and may shift how teams prioritize models, tooling, or deployment choices.
- Primary signals: AI platforms and product execution.
- Source context: The Algorithmic Bridge published or updated this item on 2026-05-04.
US government increases AI suppliers and rethinks Anthropic’s role
The US administration has added four more AI companies to its roster of favoured suppliers, with the Pentagon signing agreements with Microsoft, Reflection AI (which has yet to release a publicly-available model), Amazon, and Nvidia that mean their products can be used on...
US government increases AI suppliers and rethinks Anthropic’s role matters because it affects the policy, supply-chain, or security constraints around AI development, especially across government, model.
- Primary signals: government, model.
- Source context: AI News published or updated this item on 2026-05-06.
Supercomputer networking to accelerate large scale AI training
Supercomputer networking to accelerate large scale AI training OpenAI
Supercomputer networking to accelerate large scale AI training matters because it affects the policy, supply-chain, or security constraints around AI development, especially across compute, training.
- Primary signals: compute, training.
- Source context: OpenAI Research published or updated this item on 2026-05-05.
Gradient-based Planning for World Models at Longer Horizons
GRASP is a new gradient-based planner for learned dynamics (a “world model”) that makes long-horizon planning practical by (1) lifting the trajectory into virtual states so optimization is parallel across time, (2) adding stochasticity directly to the state iterates for...
Gradient-based Planning for World Models at Longer Horizons matters because it affects the policy, supply-chain, or security constraints around AI development, especially across state, model.
- Primary signals: state, model.
- Source context: BAIR Blog published or updated this item on 2026-04-20.
SAP: How enterprise AI governance secures profit margins
According to SAP, enterprise AI governance secures profit margins by replacing statistical guesses with deterministic control. Ask a consumer-grade model to count the words in a document, and it will often miss the mark by ten percent. Manos Raptopoulos, Global President of...
SAP: How enterprise AI governance secures profit margins matters because it affects the policy, supply-chain, or security constraints around AI development, especially across europe, model.
- Primary signals: europe, model.
- Source context: AI News published or updated this item on 2026-05-01.
Weekly Top Picks #120
Q1 earnings / Trump wants to nationalize AI / China protects its workers / ARC-AGI-3 defeats GPT-5.5 and Opus-4.7 / The "permanent underclass" / Dawkins x Claudia
Weekly Top Picks #120 matters because it affects the policy, supply-chain, or security constraints around AI development, especially across china, gpt.
- Primary signals: china, gpt.
- Source context: The Algorithmic Bridge published or updated this item on 2026-05-01.
HP and the art of AI and data for the enterprise
Ahead of the AI & Big Data Expo at the San Jose McEnery Convention Center, May 18-19, we spoke to Jerome Gabryszewski, the company’s AI & Data Science Business Development Manager about AI, processing data for AI ingestion, and local versus cloud compute. The technology media...
HP and the art of AI and data for the enterprise matters because it affects the policy, supply-chain, or security constraints around AI development, especially across compute.
- Primary signals: compute.
- Source context: AI News published or updated this item on 2026-05-06.

How to Protect Your Brain From AI in 5 Minutes
Cognitive self-defense for the AI era
How to Protect Your Brain From AI in 5 Minutes matters because it affects the policy, supply-chain, or security constraints around AI development, especially across defense.
- Primary signals: defense.
- Source context: The Algorithmic Bridge published or updated this item on 2026-04-27.
Cyber-Insecurity in the AI Era
Cyber-Insecurity in the AI Era MIT Technology Review
Cyber-Insecurity in the AI Era matters because it affects the policy, supply-chain, or security constraints around AI development, especially across security.
- Primary signals: security.
- Source context: MIT Tech Review AI published or updated this item on 2026-05-01.
Benchmarking Egocentric Multimodal Goal Inference for Assistive Wearable Agents
TL;DR: There has recently been a surge of interest in Wearable Assistant Agents: agents embodied in a wearable form factor such as smart glasses, who can take actions toward a user’s stated goal — a high-level...
There has recently been a surge of interest in Wearable Assistant Agents: agents embodied in a wearable form factor such as smart glasses, who can take actions toward a user’s stated goal — a high-level language-expressed command such as “where did I leave my keys?”, “Text...
There has recently been a surge of interest in Wearable Assistant Agents: agents embodied in a wearable form factor such as smart glasses, who can take actions toward a user’s stated goal — a high-level language-expressed command such as “where did I leave...
However, MCQ assesses discrimination, not the model’s ultimate task of generating the goal through open-ended text generation.
We ran a human predictability study, where we found that humans set a strong baseline that comprises a de facto upper bound on model performance: they show multiple choice question (MCQ) accuracy of 93%, with the best VLM achieving about 84% accuracy.
The abstract is promising, but we still need to inspect the full paper for compute cost, implementation complexity, and how broadly the gains transfer beyond the reported benchmarks.
- Problem framing: There has recently been a surge of interest in Wearable Assistant Agents: agents embodied in a wearable form factor such as smart glasses, who can take actions toward a user’s stated goal — a high-level language-expressed command such as...
- Method signal: However, MCQ assesses discrimination, not the model’s ultimate task of generating the goal through open-ended text generation.
- Evidence to watch: We ran a human predictability study, where we found that humans set a strong baseline that comprises a de facto upper bound on model performance: they show multiple choice question (MCQ) accuracy of 93%, with the best VLM achieving about...
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from NeurIPS 2025.
- Problem: There has recently been a surge of interest in Wearable Assistant Agents: agents embodied in a wearable form factor such as smart glasses, who can take actions toward a user’s stated goal — a high-level...
- Approach: However, MCQ assesses discrimination, not the model’s ultimate task of generating the goal through open-ended text generation.
- Result signal: We ran a human predictability study, where we found that humans set a strong baseline that comprises a de facto upper bound on model performance: they show multiple choice question (MCQ) accuracy of...
- Conference context: NeurIPS 2025 Datasets and Benchmarks Track
- The abstract is promising, but we still need to inspect the full paper for compute cost, implementation complexity, and how broadly the gains transfer beyond the reported benchmarks.
Improve Temporal Reasoning in Multimodal Large Language Models via Video Contrastive Decoding
TL;DR: A major distinction between video and image understanding is that the former requires reasoning over time.
A major distinction between video and image understanding is that the former requires reasoning over time. Existing Video Large Language Models (VLLMs) demonstrate promising performance in general video understanding, such as brief captioning or object recognition within...
A major distinction between video and image understanding is that the former requires reasoning over time.
Such corruption induces time-insensitive wrong responses from the model, which are then contrastively avoided when generating the final correct output.
Existing Video Large Language Models (VLLMs) demonstrate promising performance in general video understanding, such as brief captioning or object recognition within individual frames.
The abstract is promising, but we still need to inspect the full paper for compute cost, implementation complexity, and how broadly the gains transfer beyond the reported benchmarks.
- Problem framing: A major distinction between video and image understanding is that the former requires reasoning over time.
- Method signal: Such corruption induces time-insensitive wrong responses from the model, which are then contrastively avoided when generating the final correct output.
- Evidence to watch: Existing Video Large Language Models (VLLMs) demonstrate promising performance in general video understanding, such as brief captioning or object recognition within individual frames.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from NeurIPS 2025.
- Problem: A major distinction between video and image understanding is that the former requires reasoning over time.
- Approach: Such corruption induces time-insensitive wrong responses from the model, which are then contrastively avoided when generating the final correct output.
- Result signal: Existing Video Large Language Models (VLLMs) demonstrate promising performance in general video understanding, such as brief captioning or object recognition within individual frames.
- Conference context: NeurIPS 2025 Main Conference Track
- The abstract is promising, but we still need to inspect the full paper for compute cost, implementation complexity, and how broadly the gains transfer beyond the reported benchmarks.
MLLM-For3D: Adapting Multimodal Large Language Model for 3D Reasoning Segmentation
TL;DR: Reasoning segmentation aims to segment target objects in complex scenes based on human intent and spatial reasoning.
Reasoning segmentation aims to segment target objects in complex scenes based on human intent and spatial reasoning. While recent multimodal large language models (MLLMs) have demonstrated impressive 2D image reasoning segmentation, adapting these capabilities to 3D scenes...
The primary challenge lies in the absence of 3D context and spatial consistency across multiple views, causing the model to hallucinate objects that do not exist and fail to target objects consistently.
In this paper, we introduce MLLM-For3D, a simple yet effective framework that transfers knowledge from 2D MLLMs to 3D scene understanding.
While recent multimodal large language models (MLLMs) have demonstrated impressive 2D image reasoning segmentation, adapting these capabilities to 3D scenes remains underexplored.
The abstract is promising, but we still need to inspect the full paper for compute cost, implementation complexity, and how broadly the gains transfer beyond the reported benchmarks.
- Problem framing: The primary challenge lies in the absence of 3D context and spatial consistency across multiple views, causing the model to hallucinate objects that do not exist and fail to target objects consistently.
- Method signal: In this paper, we introduce MLLM-For3D, a simple yet effective framework that transfers knowledge from 2D MLLMs to 3D scene understanding.
- Evidence to watch: While recent multimodal large language models (MLLMs) have demonstrated impressive 2D image reasoning segmentation, adapting these capabilities to 3D scenes remains underexplored.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from NeurIPS 2025.
- Problem: The primary challenge lies in the absence of 3D context and spatial consistency across multiple views, causing the model to hallucinate objects that do not exist and fail to target objects consistently.
- Approach: In this paper, we introduce MLLM-For3D, a simple yet effective framework that transfers knowledge from 2D MLLMs to 3D scene understanding.
- Result signal: While recent multimodal large language models (MLLMs) have demonstrated impressive 2D image reasoning segmentation, adapting these capabilities to 3D scenes remains underexplored.
- Conference context: NeurIPS 2025 Main Conference Track
- The abstract is promising, but we still need to inspect the full paper for compute cost, implementation complexity, and how broadly the gains transfer beyond the reported benchmarks.
ReCAP: Recursive Context-Aware Reasoning and Planning for Large Language Model Agents
TL;DR: Long-horizon tasks requiring multi-step reasoning and dynamic re-planning remain challenging for large language models (LLMs).
Long-horizon tasks requiring multi-step reasoning and dynamic re-planning remain challenging for large language models (LLMs). Sequential prompting methods are prone to context drift, loss of goal information, and recurrent failure cycles, while hierarchical prompting methods...
Long-horizon tasks requiring multi-step reasoning and dynamic re-planning remain challenging for large language models (LLMs).
We introduce ReCAP (Recursive Context-Aware Reasoning and Planning), a hierarchical framework with shared context for reasoning and planning in LLMs.
Experiments demonstrate that ReCAP substantially improves subgoal alignment and success rates on various long-horizon reasoning benchmarks, achieving a 32\% gain on synchronous Robotouille and a 29\% improvement on asynchronous Robotouille under the strict pass@1 protocol.
The abstract is promising, but we still need to inspect the full paper for compute cost, implementation complexity, and how broadly the gains transfer beyond the reported benchmarks.
- Problem framing: Long-horizon tasks requiring multi-step reasoning and dynamic re-planning remain challenging for large language models (LLMs).
- Method signal: We introduce ReCAP (Recursive Context-Aware Reasoning and Planning), a hierarchical framework with shared context for reasoning and planning in LLMs.
- Evidence to watch: Experiments demonstrate that ReCAP substantially improves subgoal alignment and success rates on various long-horizon reasoning benchmarks, achieving a 32\% gain on synchronous Robotouille and a 29\% improvement on asynchronous...
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from NeurIPS 2025.
- Problem: Long-horizon tasks requiring multi-step reasoning and dynamic re-planning remain challenging for large language models (LLMs).
- Approach: We introduce ReCAP (Recursive Context-Aware Reasoning and Planning), a hierarchical framework with shared context for reasoning and planning in LLMs.
- Result signal: Experiments demonstrate that ReCAP substantially improves subgoal alignment and success rates on various long-horizon reasoning benchmarks, achieving a 32\% gain on synchronous Robotouille and a 29\%...
- Conference context: NeurIPS 2025 Main Conference Track
- The abstract is promising, but we still need to inspect the full paper for compute cost, implementation complexity, and how broadly the gains transfer beyond the reported benchmarks.
Skill1: Unified Evolution of Skill-Augmented Agents via Reinforcement Learning
TL;DR: Skill1 is a unified framework that trains a single policy to simultaneously evolve skill selection, utilization, and distillation capabilities using a shared task-outcome objective, demonstrating superior performance...
Skill1 is a unified framework that trains a single policy to simultaneously evolve skill selection, utilization, and distillation capabilities using a shared task-outcome objective, demonstrating superior performance over existing baselines in complex task environments. A...
Skill1 is a unified framework that trains a single policy to simultaneously evolve skill selection, utilization, and distillation capabilities using a shared task-outcome objective, demonstrating superior performance over existing baselines in complex task...
We propose Skill1, a framework that trains a single policy to co-evolve skill selection , utilization, and distillation toward a shared task-outcome objective .
Skill1 is a unified framework that trains a single policy to simultaneously evolve skill selection, utilization, and distillation capabilities using a shared task-outcome objective, demonstrating superior performance over existing baselines in complex task environments.
The reported improvement still needs a closer check on benchmark scope, ablations, and whether the method keeps working outside the authors' evaluation setup.
- Problem framing: Skill1 is a unified framework that trains a single policy to simultaneously evolve skill selection, utilization, and distillation capabilities using a shared task-outcome objective, demonstrating superior performance over existing...
- Method signal: We propose Skill1, a framework that trains a single policy to co-evolve skill selection , utilization, and distillation toward a shared task-outcome objective .
- Evidence to watch: Skill1 is a unified framework that trains a single policy to simultaneously evolve skill selection, utilization, and distillation capabilities using a shared task-outcome objective, demonstrating superior performance over existing...
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: Skill1 is a unified framework that trains a single policy to simultaneously evolve skill selection, utilization, and distillation capabilities using a shared task-outcome objective, demonstrating superior...
- Approach: We propose Skill1, a framework that trains a single policy to co-evolve skill selection , utilization, and distillation toward a shared task-outcome objective .
- Result signal: Skill1 is a unified framework that trains a single policy to simultaneously evolve skill selection, utilization, and distillation capabilities using a shared task-outcome objective, demonstrating...
- Community traction: Hugging Face Papers shows 52 votes for this paper.
- The reported improvement still needs a closer check on benchmark scope, ablations, and whether the method keeps working outside the authors' evaluation setup.

MiA-Signature: Approximating Global Activation for Long-Context Understanding
TL;DR: Researchers propose a compressed representation method for global activation patterns in large language models that approximates full activation states while maintaining computational efficiency and improving...
Researchers propose a compressed representation method for global activation patterns in large language models that approximates full activation states while maintaining computational efficiency and improving performance in long-context tasks. A growing body of work in...
Researchers propose a compressed representation method for global activation patterns in large language models that approximates full activation states while maintaining computational efficiency and improving performance in long-context tasks.
Inspired by this idea, we introduce the concept of Mindscape Activation Signature (MiA-Signature), a compressed representation of the global activation pattern induced by a query.
Researchers propose a compressed representation method for global activation patterns in large language models that approximates full activation states while maintaining computational efficiency and improving performance in long-context tasks.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: Researchers propose a compressed representation method for global activation patterns in large language models that approximates full activation states while maintaining computational efficiency and improving performance in long-context tasks.
- Method signal: Inspired by this idea, we introduce the concept of Mindscape Activation Signature (MiA-Signature), a compressed representation of the global activation pattern induced by a query.
- Evidence to watch: Researchers propose a compressed representation method for global activation patterns in large language models that approximates full activation states while maintaining computational efficiency and improving performance in long-context...
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: Researchers propose a compressed representation method for global activation patterns in large language models that approximates full activation states while maintaining computational efficiency and...
- Approach: Inspired by this idea, we introduce the concept of Mindscape Activation Signature (MiA-Signature), a compressed representation of the global activation pattern induced by a query.
- Result signal: Researchers propose a compressed representation method for global activation patterns in large language models that approximates full activation states while maintaining computational efficiency and...
- Community traction: Hugging Face Papers shows 37 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
Beyond Semantic Similarity: Rethinking Retrieval for Agentic Search via Direct Corpus Interaction
TL;DR: Direct corpus interaction enables more effective agentic search by allowing agents to query raw text directly, outperforming traditional retrieval methods in complex tasks.
Direct corpus interaction enables more effective agentic search by allowing agents to query raw text directly, outperforming traditional retrieval methods in complex tasks. Modern retrieval systems , whether lexical or semantic, expose a corpus through a fixed similarity...
Direct corpus interaction enables more effective agentic search by allowing agents to query raw text directly, outperforming traditional retrieval methods in complex tasks.
Modern retrieval systems , whether lexical or semantic, expose a corpus through a fixed similarity interface that compresses access into a single top-k retrieval step before reasoning.
Direct corpus interaction enables more effective agentic search by allowing agents to query raw text directly, outperforming traditional retrieval methods in complex tasks.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: Direct corpus interaction enables more effective agentic search by allowing agents to query raw text directly, outperforming traditional retrieval methods in complex tasks.
- Method signal: Modern retrieval systems , whether lexical or semantic, expose a corpus through a fixed similarity interface that compresses access into a single top-k retrieval step before reasoning.
- Evidence to watch: Direct corpus interaction enables more effective agentic search by allowing agents to query raw text directly, outperforming traditional retrieval methods in complex tasks.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: Direct corpus interaction enables more effective agentic search by allowing agents to query raw text directly, outperforming traditional retrieval methods in complex tasks.
- Approach: Modern retrieval systems , whether lexical or semantic, expose a corpus through a fixed similarity interface that compresses access into a single top-k retrieval step before reasoning.
- Result signal: Direct corpus interaction enables more effective agentic search by allowing agents to query raw text directly, outperforming traditional retrieval methods in complex tasks.
- Community traction: Hugging Face Papers shows 41 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.

RaguTeam at SemEval-2026 Task 8: Meno and Friends in a Judge-Orchestrated LLM Ensemble for Faithful Multi-Turn Response Generation
TL;DR: A heterogeneous ensemble of seven large language models with dual prompting strategies achieved top performance in the SemEval-2026 MTRAGEval task through judge selection and demonstrated the importance of model...
A heterogeneous ensemble of seven large language models with dual prompting strategies achieved top performance in the SemEval-2026 MTRAGEval task through judge selection and demonstrated the importance of model diversity. We present our winning system for Task~B (generation...
A heterogeneous ensemble of seven large language models with dual prompting strategies achieved top performance in the SemEval-2026 MTRAGEval task through judge selection and demonstrated the importance of model diversity.
We present our winning system for Task~B (generation with reference passages) in SemEval-2026 Task~8: MTRAGEval.
A heterogeneous ensemble of seven large language models with dual prompting strategies achieved top performance in the SemEval-2026 MTRAGEval task through judge selection and demonstrated the importance of model diversity.
The reported improvement still needs a closer check on benchmark scope, ablations, and whether the method keeps working outside the authors' evaluation setup.
- Problem framing: A heterogeneous ensemble of seven large language models with dual prompting strategies achieved top performance in the SemEval-2026 MTRAGEval task through judge selection and demonstrated the importance of model diversity.
- Method signal: We present our winning system for Task~B (generation with reference passages) in SemEval-2026 Task~8: MTRAGEval.
- Evidence to watch: A heterogeneous ensemble of seven large language models with dual prompting strategies achieved top performance in the SemEval-2026 MTRAGEval task through judge selection and demonstrated the importance of model diversity.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: A heterogeneous ensemble of seven large language models with dual prompting strategies achieved top performance in the SemEval-2026 MTRAGEval task through judge selection and demonstrated the importance of...
- Approach: We present our winning system for Task~B (generation with reference passages) in SemEval-2026 Task~8: MTRAGEval.
- Result signal: A heterogeneous ensemble of seven large language models with dual prompting strategies achieved top performance in the SemEval-2026 MTRAGEval task through judge selection and demonstrated the...
- Community traction: Hugging Face Papers shows 35 votes for this paper.
- The reported improvement still needs a closer check on benchmark scope, ablations, and whether the method keeps working outside the authors' evaluation setup.

Continuous Latent Diffusion Language Model
TL;DR: Cola DLM presents a hierarchical latent diffusion language model that uses text-to-latent mapping, global semantic prior modeling, and conditional decoding to achieve efficient text generation with flexible...
Cola DLM presents a hierarchical latent diffusion language model that uses text-to-latent mapping, global semantic prior modeling, and conditional decoding to achieve efficient text generation with flexible non-autoregressive inductive bias. Large language models have...
Cola DLM presents a hierarchical latent diffusion language model that uses text-to-latent mapping, global semantic prior modeling, and conditional decoding to achieve efficient text generation with flexible non-autoregressive inductive bias.
We propose Cola DLM, a hierarchical latent diffusion language model that frames text generation through hierarchical information decomposition.
Cola DLM presents a hierarchical latent diffusion language model that uses text-to-latent mapping, global semantic prior modeling, and conditional decoding to achieve efficient text generation with flexible non-autoregressive inductive bias.
The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
- Problem framing: Cola DLM presents a hierarchical latent diffusion language model that uses text-to-latent mapping, global semantic prior modeling, and conditional decoding to achieve efficient text generation with flexible non-autoregressive inductive bias.
- Method signal: We propose Cola DLM, a hierarchical latent diffusion language model that frames text generation through hierarchical information decomposition.
- Evidence to watch: Cola DLM presents a hierarchical latent diffusion language model that uses text-to-latent mapping, global semantic prior modeling, and conditional decoding to achieve efficient text generation with flexible non-autoregressive inductive bias.
- Read-through priority: the PDF is available, so this is a good candidate for checking tables, ablations, and scaling tradeoffs beyond the abstract from Hugging Face Papers / arXiv.
- Problem: Cola DLM presents a hierarchical latent diffusion language model that uses text-to-latent mapping, global semantic prior modeling, and conditional decoding to achieve efficient text generation with flexible...
- Approach: We propose Cola DLM, a hierarchical latent diffusion language model that frames text generation through hierarchical information decomposition.
- Result signal: Cola DLM presents a hierarchical latent diffusion language model that uses text-to-latent mapping, global semantic prior modeling, and conditional decoding to achieve efficient text generation with...
- Community traction: Hugging Face Papers shows 38 votes for this paper.
- The summary does not include concrete numbers, so the practical size of the gain and the tradeoff against latency or data cost are still unclear.
Issue routing and exits.
The daily edition stays aligned with the rest of the site while keeping the full issue readable end to end.
Navigation
Public desks
Issue
- 05/08/2026
- 75 total analyzed
- Readable issue route